Audio
Pipeline
- ML: audio -> denoise -> feature extraction(STFT) -> feature selection (PCA) -> Classification(ML:SVM/KNN/RF)
- DL: audio -> denoise -> feature extraction(STFT) -> feature selection (PCA) -> Classification(DL:1DConv/TCN)
Feature extraction tools
1. librosa——c++/py
用于处理audio和music的python tool——py 39M beat_track和onset_detect
- Librosa doc https://librosa.org/doc/latest/index.html
- Librosa example gallery https://librosa.org/librosa_gallery/index.html
- Librosa处理音频信号 https://huailiang.github.io/blog/2019/sound/
LibrosaCpp——c++ 19M
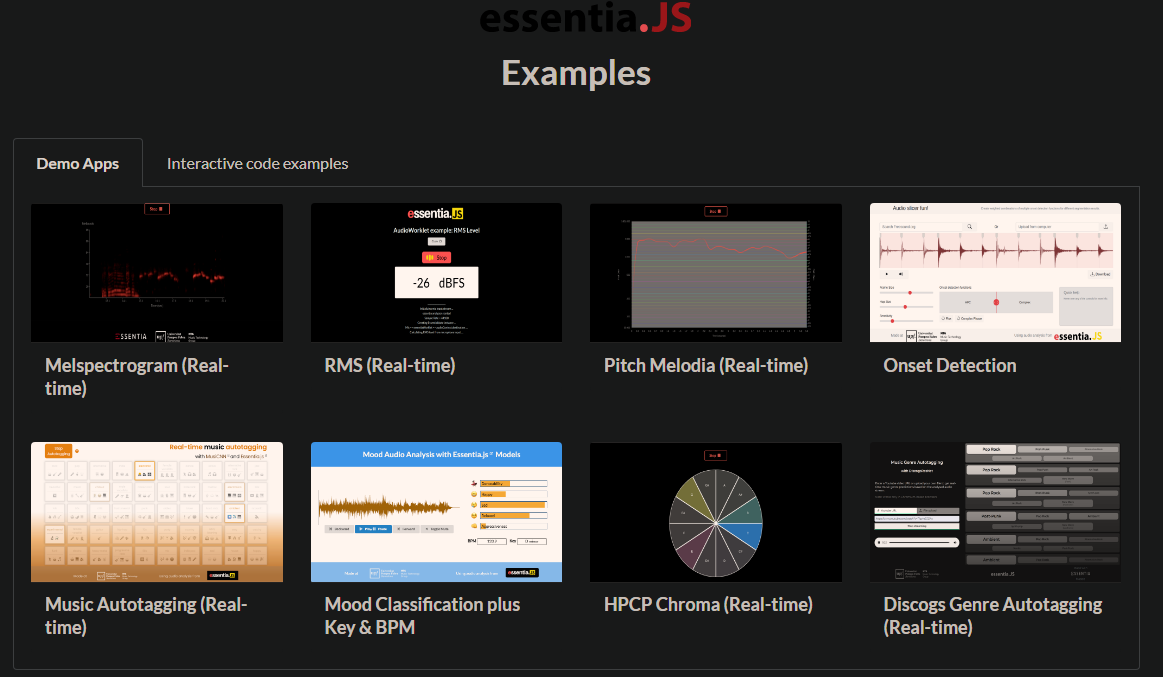
2. essentia——c++/py
可以提取的rhythm descriptor里包括beat detection, BPM, onset detection, rhythm transform, beat loudness
https://mtg.github.io/essentia.js/examples/
https://essentia.upf.edu/models.html
https://mtg.github.io/essentia.js/examples/demos/mood-classifiers/
3. aubio——c/python
https://github.com/aubio/aubio
https://aubio.org/manual/latest/
aubio provide several algorithms and routines, including:
- several onset detection methods
- different pitch detection methods
- tempo tracking and beat detection
- MFCC (mel-frequency cepstrum coefficients)
- FFT and phase vocoder
- up/down-sampling
- digital filters (low pass, high pass, and more)
- spectral filtering
- transient/steady-state separation
- sound file read and write access
- various mathematics utilities for music applications
4. madmom——python
https://github.com/CPJKU/madmom
Task 1 Baby Crying Detection
Related info
Baby cry detection - Building the model https://github.com/giulbia/baby_cry_detection
Baby cry detection - Deployment on Raspberry Pi https://github.com/giulbia/baby_cry_rpi
ESC-50: Dataset for Environmental Sound Classification https://github.com/karolpiczak/ESC-50
Common features
电信号
https://github.com/LeoHsiao1/Notes
模拟信号(analog signal):电平连续变化的电信号。
数字信号(digital signal):只有高低两种电平的脉冲电压信号。
- 数字信号传输时的误码率低,速度快。
将模拟信号转换成数字信号(即数字化)的主要方法是
脉冲编码调制,分为以下三步:
- 采样:从电平连续变化的模拟信号中每隔一定时间取一个幅值作为样本,代表原信号。
- 量化:将样本幅值分级量化。
- 编码:将样本量级表示成二进制。
- 采样:从电平连续变化的模拟信号中每隔一定时间取一个幅值作为样本,代表原信号。
# features
zcr_feat = self.compute_librosa_features(audio_data=audio_data, feat_name='zero_crossing_rate')
rmse_feat = self.compute_librosa_features(audio_data=audio_data, feat_name='rmse')
mfcc_feat = self.compute_librosa_features(audio_data=audio_data, feat_name= 'mfcc')
spectral_centroid_feat = self.compute_librosa_features(audio_data=audio_data, feat_name='spectral_centroid')
spectral_rolloff_feat = self.compute_librosa_features(audio_data=audio_data, feat_name='spectral_rolloff')
spectral_bandwidth_feat = self.compute_librosa_features(audio_data=audio_data, feat_name='spectral_bandwidth')MFCC
https://tianchi.aliyun.com/mas-notebook/preview/185322/208998/-1?lang=
http://fancyerii.github.io/books/mfcc/
https://github.com/tosonw/MFCC
- 过零率 (Zero Crossing Rate)
- 频谱质心 (Spectral Centroid)
- 声谱衰减 (Spectral Roll-off)
- 梅尔频率倒谱系数 (Mel-frequency cepstral coefficients ,MFCC)
- 色度频率 (Chroma Frequencies)
FFT STFT

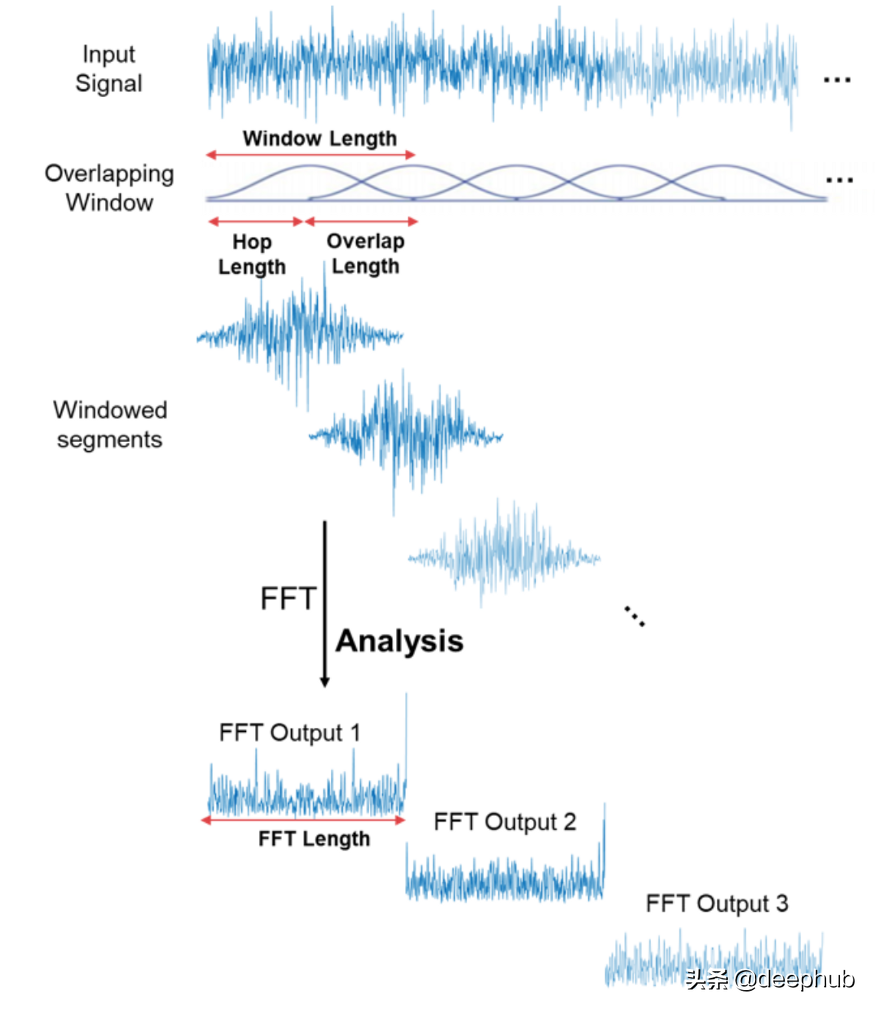
C 直接用
https://github.com/Troy-Wang/BabyCryDetector/tree/master/Monitor_c
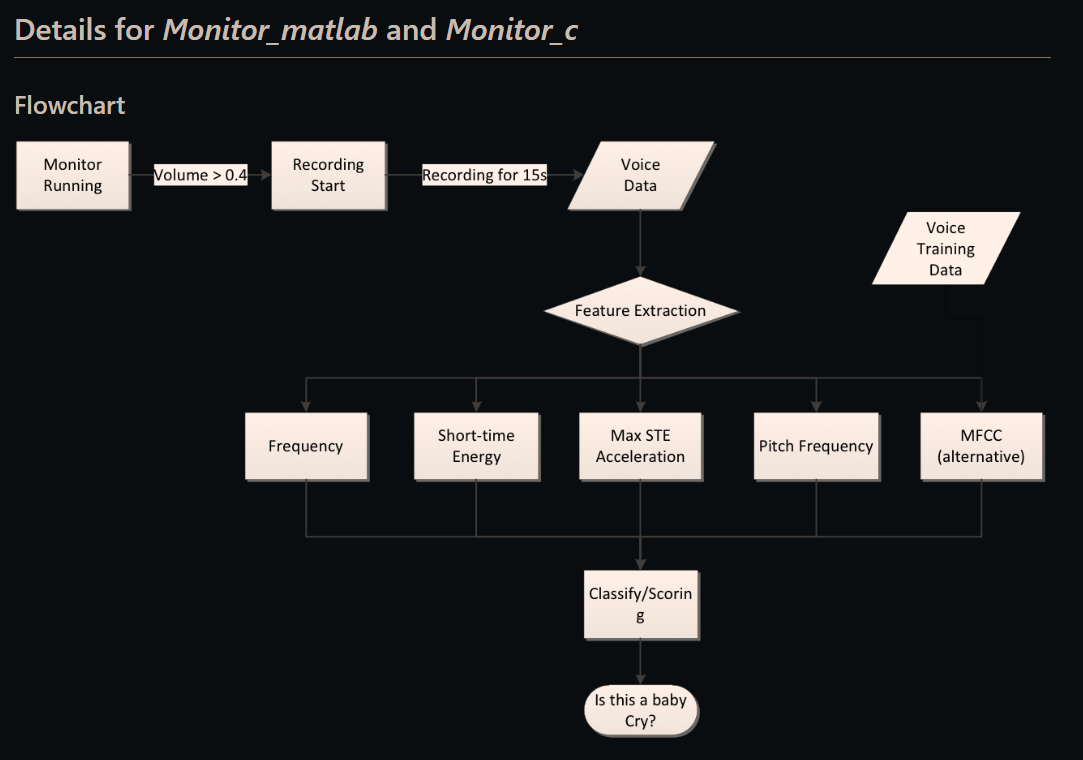
if(feature_Freq > stdAvgFreq)
{
score = score + 2;
printf("freq yes");
}
if(feature_PitchFreq > stdPitchFreq)
{
score = score + 5;
printf("pitch freq yes");
}
if(feature_STE > stdSTE)
{
score = score + 1;
printf("ste yes");
}
if(feature_STEAcc > stdAcc)
{
score = score + 1;
printf("steacc yes");
}
if(feature_ZCR > stdZCR)
{
score = score + 1;
printf("zcr yes");
}
printf("%d\n",score);
if(score >= 5)
{
printf("baby cry!\n");
return 1;
}
else
return 0;Others reference
https://github.com/Ananya-github/Audio-signal-classification 可能有用
https://github.com/Troy-Wang/BabyCryDetector
https://towardsdatascience.com/deep-learning-for-classifying-audio-of-babies-crying-9a29e057f7ca
https://chatterbaby.org/pages/index_ch cry类别
https://zenodo.org/record/1290750#.Y-C7MHZBxaR 音乐乐器分类数据集
Smart Detection (Cry, Motion, Noise) https://support.lollipop.camera/hc/en-us/articles/4410890181273-Smart-Detection-Cry-Motion-Noise-#h_01FNT82C0PF0B2M46F78YETY4V

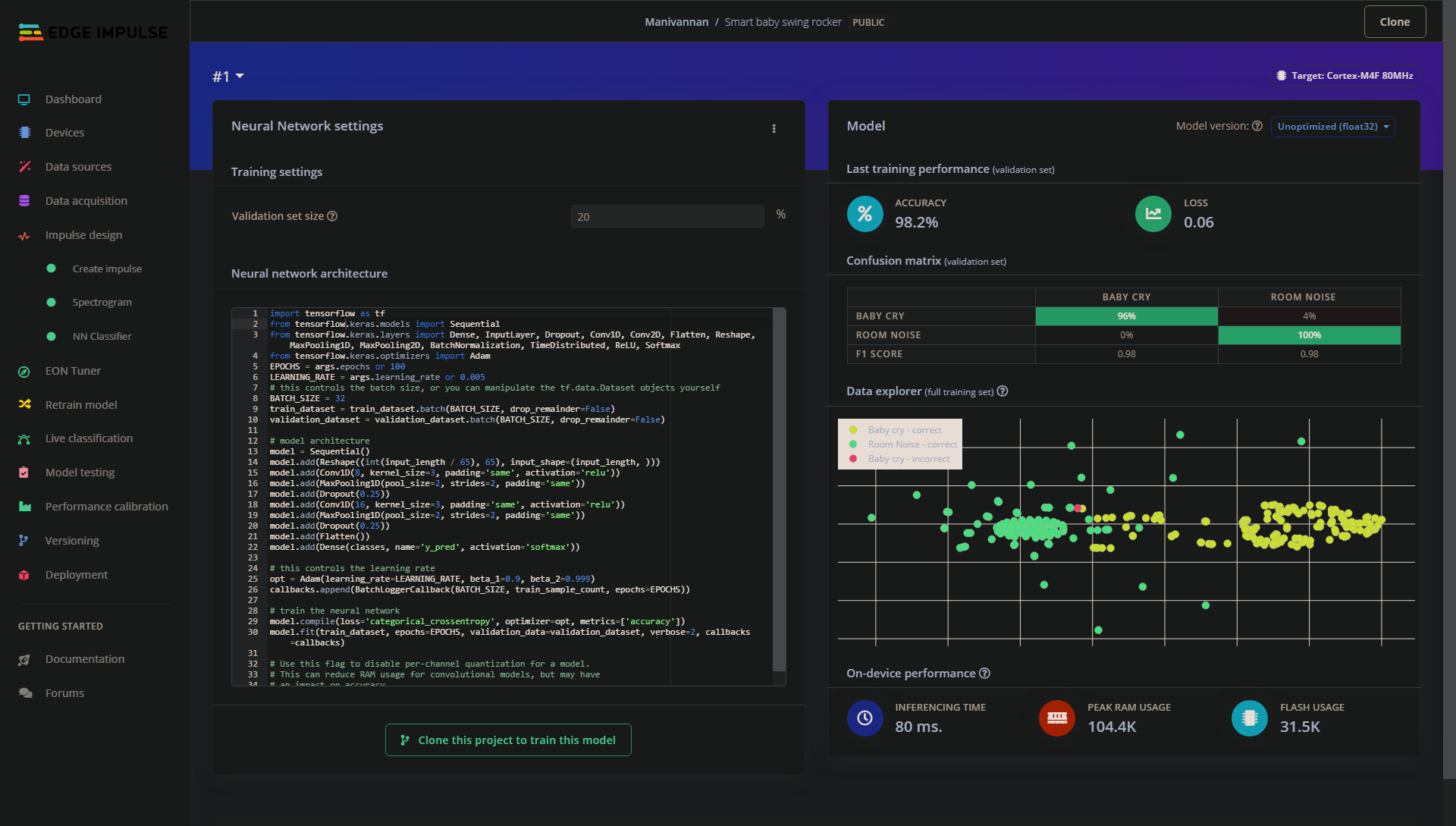
NN model https://studio.edgeimpulse.com/public/134216/latest/devices
paper:Development of a Baby Cry Monitoring Device
Pitch detection https://www.kaggle.com/code/lrthtn/pitch-detection/notebook
Task 2 Music Information Retrieval (MIR)
Beats and tempo
https://cloud.tencent.com/developer/article/1634207

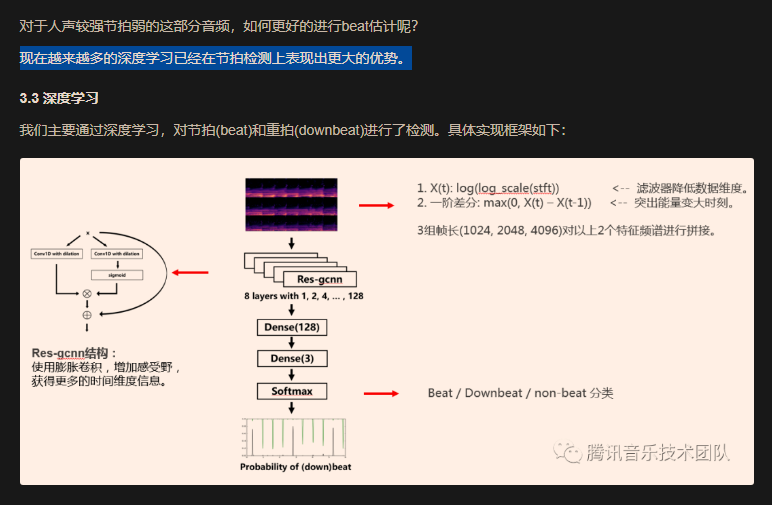
《Beat Tracking by Dynamic Programming》
https://github.com/librosa/librosa/blob/main/librosa/beat.py
https://github.com/bineferg/MIR-BeatTracker-DP
https://tempobeatdownbeat.github.io/tutorial/ch2_basics/baseline.html
https://tempobeatdownbeat.github.io/tutorial/ch3_going_deep/overview.html

Joint Beat and Downbeat Tracking with Recurrent Neural Networks
https://blog.csdn.net/zjuPeco/article/details/120184032
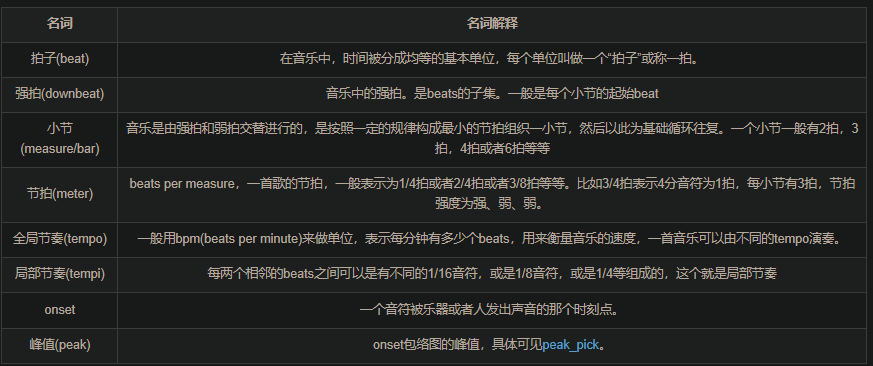

https://tempobeatdownbeat.github.io/tutorial/ch3_going_deep/table.html
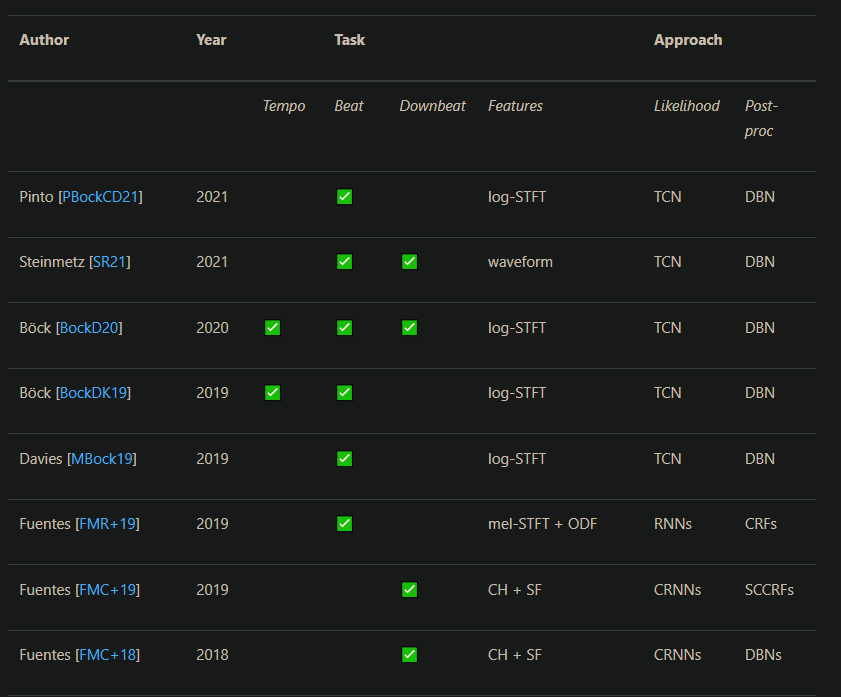
BeatNet https://github.com/mjhydri/beatnet
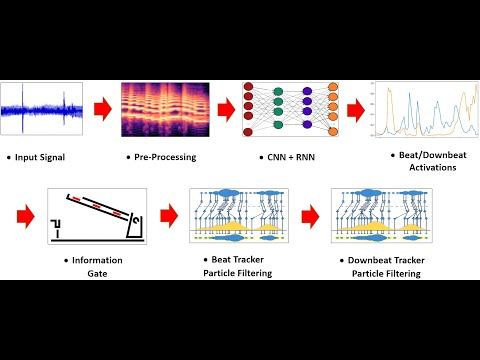
For the input feature extraction and the raw state space generation, Librosa and Madmom libraries are ustilzed respectively.
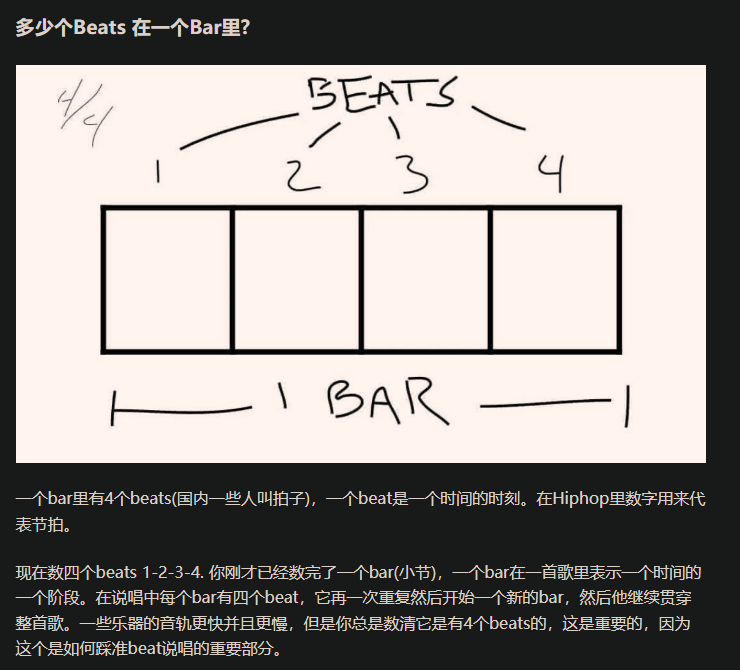
Bar https://zhuanlan.zhihu.com/p/105124027

Datasets
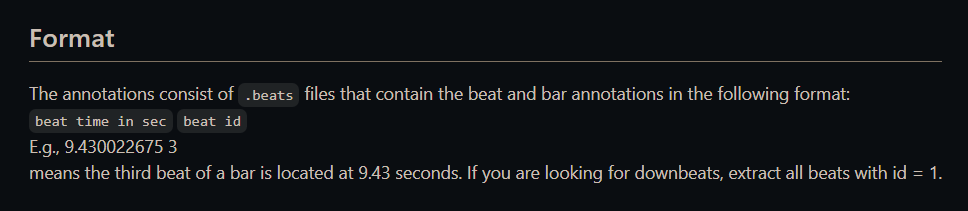
- SMC
- JCS 22首
- GiantSteps (tempo+genre) datasets https://github.com/GiantSteps/giantsteps-tempo-dataset
MIR技术
A Tutorial on Deep Learning for Music Information Retriveal
https://zhuanlan.zhihu.com/p/84756021

Experiments
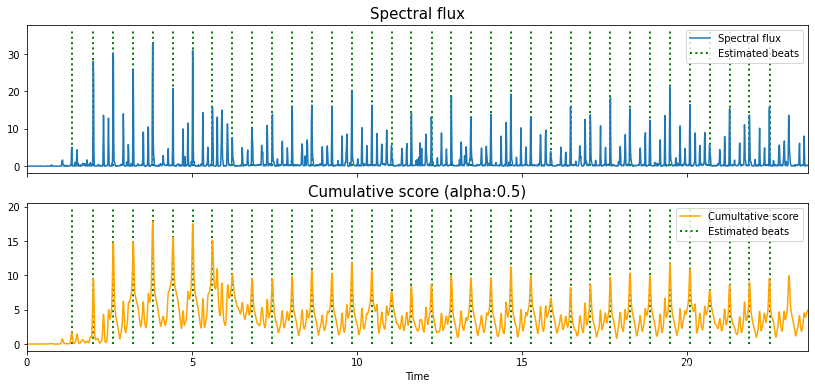
librosa.beat.beat_track
https://librosa.org/doc/main/generated/librosa.beat.beat_track.html
Returns
tempo float [scalar, non-negative]estimated global tempo (in beats per minute)
beatsnp.ndarray [shape=(m,)]estimated beat event locations in the specified units (default is frame indices)In [7]: tempo, beats = librosa.beat.beat_track(y=y, sr=sr) In [8]: tempo Out[8]: 89.10290948275862 In [9]: beats Out[9]:
array([ 23, 52, 81, 110, 139, 169, 198, 227, 257, 286, 316,
344, 373, 402, 431, 460, 489, 519, 549, 578, 606, 636,
665, 695, 724, 753, 782, 811, 840, 864, 890, 919, 948,
977, 1006, 1036, 1065, 1095, 1123, 1152, 1181, 1210, 1239])
In [10]: librosa.frames_to_time(beats, sr=sr)
Out[10]:
array([ 0.53405896, 1.20743764, 1.88081633, 2.55419501, 3.2275737 ,
3.92417234, 4.59755102, 5.27092971, 5.96752834, 6.64090703,
7.33750567, 7.9876644 , 8.66104308, 9.33442177, 10.00780045,
10.68117914, 11.35455782, 12.05115646, 12.7477551 , 13.42113379,
14.07129252, 14.76789116, 15.44126984, 16.13786848, 16.81124717,
17.48462585, 18.15800454, 18.83138322, 19.5047619 , 20.06204082,
20.66575964, 21.33913832, 22.01251701, 22.68589569, 23.35927438,
24.05587302, 24.7292517 , 25.42585034, 26.07600907, 26.74938776,
27.42276644, 28.09614512, 28.76952381])
In [13]: len(beats)
Out[13]: 43
In [14]: 60/89
Out[14]: 0.6741573033707865 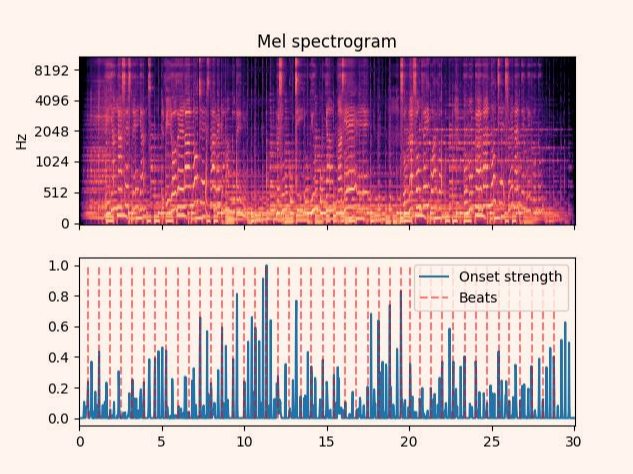
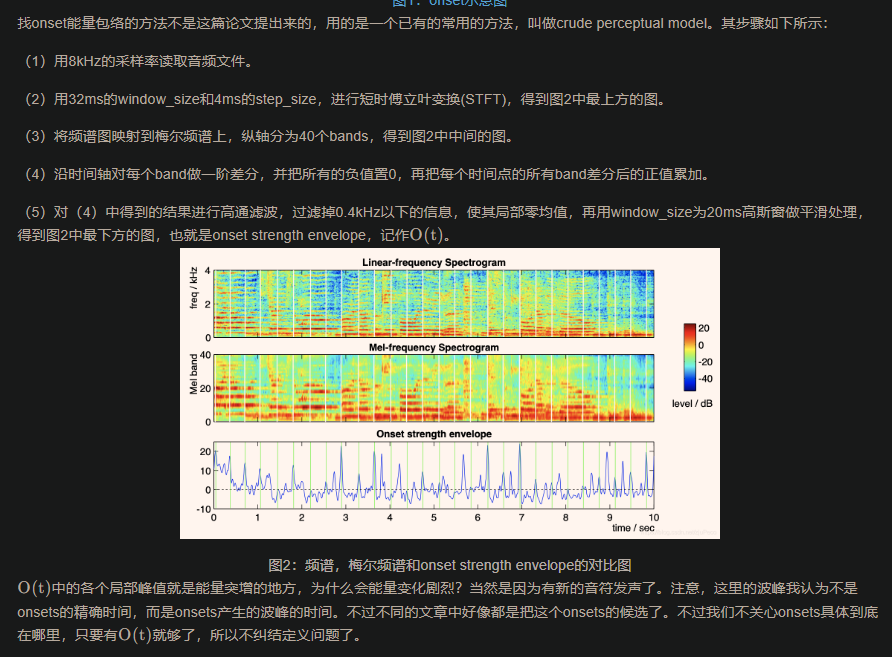
Deployment
1 ML https://github.com/bBobxx/statistical-learning
2 feature extraction



