TryOnDiffusion: A Tale of Two UNets

Abstract
- key challenge: 合成照片写实级的保留衣服细节,同时形变到相应的人体姿态和形态上
- 本文提出了diffusion-based架构,统一了2个UNets,即为paralle-UNet
- 衣服形变:通过cross attention机制进行隐式形变
- 衣服形变和人体混合: 将2个任务序列统一为一个过程
Contributions
- 1k分辨率,复杂body pose,保留衣服细节(图案,文字,标签)
- 提出parralle-UNet用attention实现隐式warping,而且将warping和blending统一为一个网络
Related Work
- Image-Based Virtual Try-On
- previous works将try-on分解为2个子任务 warping 和 blending,比如VTTON利用TPS进行warping,ClothFlow利用flow fields进行warping。VITON-HD, HR-VITON提高了生成图像的分辨率到1K。SDAFN通过deformable attention提高了质量。
- 但是上述方法都存在misalignment没有对齐问题,原因是通过显式的warping或者flow estimation带来的对齐误差。
- Tryongan利用unpaired数据训练 pose-guided stylegan2,在latent space进行优化,但是隐空间会丢失衣服的细节
- Diffusion Models
- 比GAN有很好的稳定性和更容易收敛
- 使用通道拼接的UNet架构,在图像翻译问题上效果很好
- 但是,garment warping是一个非线性问题,不适合通道拼接,所以提出了parallel-UNet,通过cross attention实现implicitly warping
Methodology
Overview
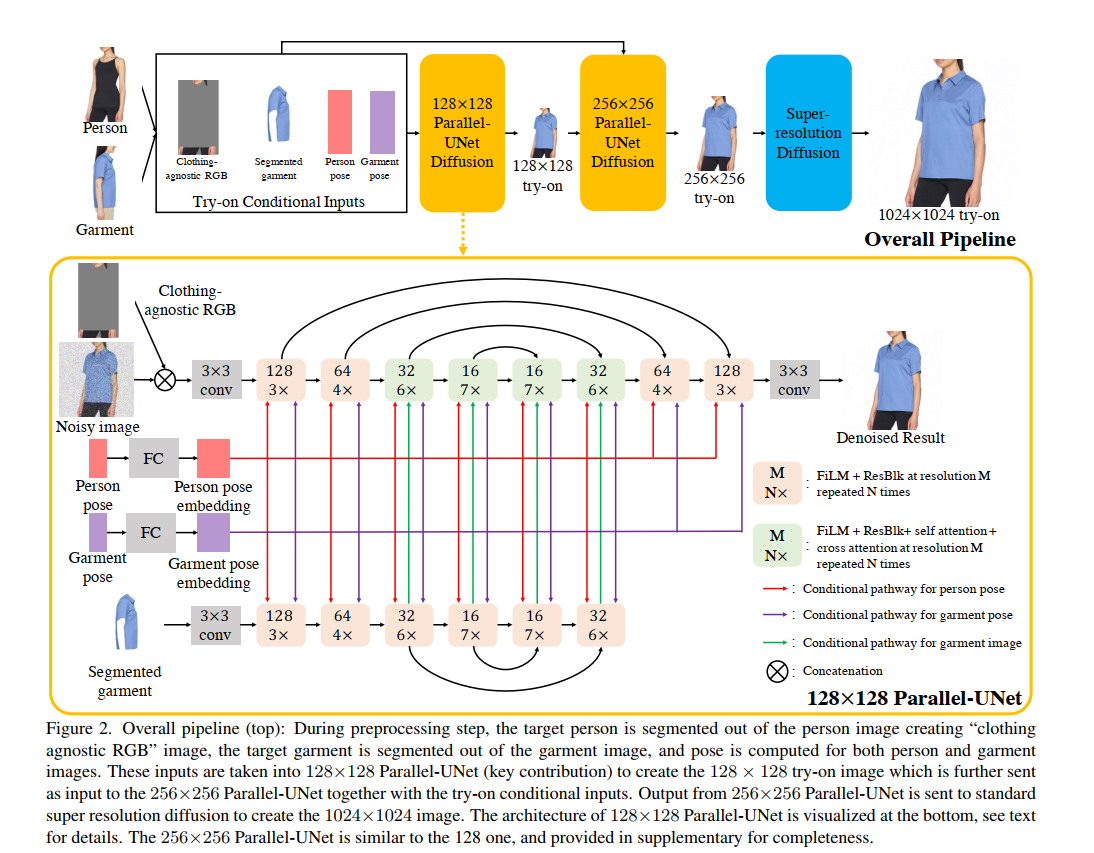
Preprocessing of inputs
估计person和garment的segmentation和keypoints
对person,对garment因为clothing-agnostic RGB described in VITON-HD 存在衣服信息泄露,需要将cloth info去掉,同时复制粘贴只保留了三部分head hand lower-body
Cascaded Diffusion Models for Try-On
包括1个基本的diffusion模型和2个超分diffusion模型
- base diffusion model
- 128X128 parallet-unet
- 输入的noise进行conditioning augmentation
- super-resolution (SR) diffusion models
- 128X128 -> 256X256 (tryon stage)
- 256X256 parallet-unet
- 256X256 -> 1024X1024 (only super resolution stage)
- as Efficient-UNet introduced by Imagen
- Photorealistic text-to-image diffusion models with deep language understanding
- https://arxiv.org/abs/2205.11487
- as Efficient-UNet introduced by Imagen
- 128X128 -> 256X256 (tryon stage)
Parallel-UNet
- Implicit warping
- 不能直接用通道拼接方法,因为传统的UNet使用空间卷积和空间自注意力,这些操作本省就有很强的像素级bias
- 提出cross attention,结合多头学习不同表征子空间特征
Combining warp and blend in a single pass
1个person unet
- 通过通道拼接作为输入
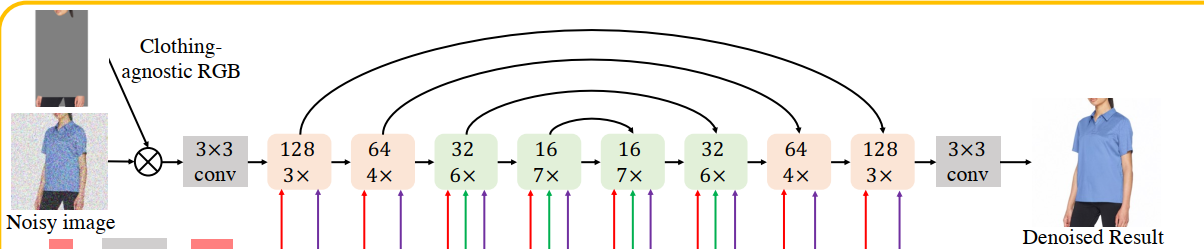
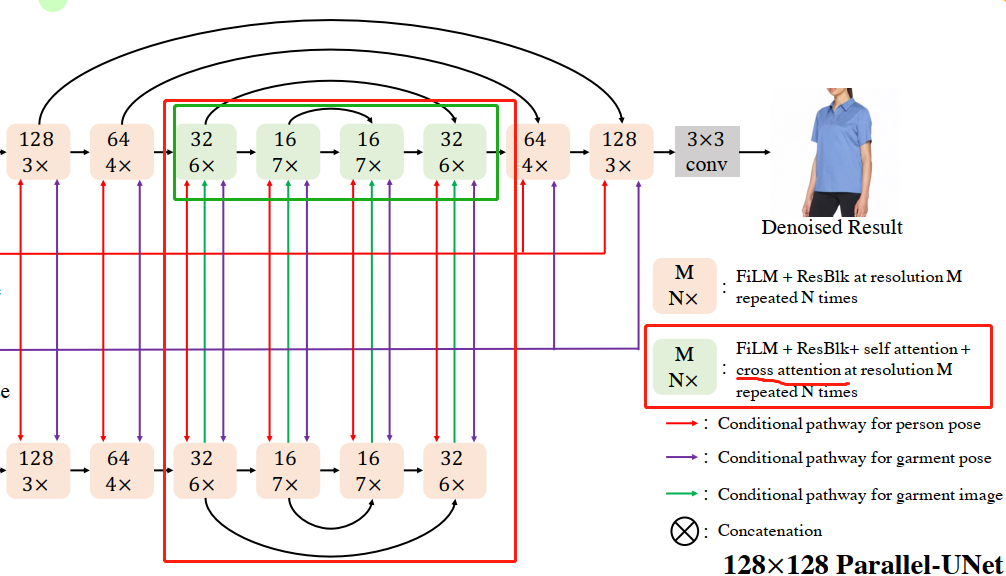
1个garment unet
- 通过cross attention将衣服特征融合到目标图像
- 在32X32block出提前停止,

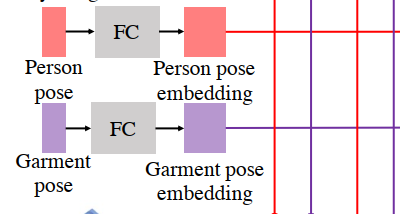
cross attention
person和garment的pose作为guidence非常必要

Experiments
Datasets
- 400万张paried dataset进行训练,每个sample都是同一个人穿同一件衣服不同姿态
- 6000张unpaired 进行测试, 每个sample都是2个不同的人穿2件不同衣服,2种不同姿态
- 图像都crop-resize到1K分辨率,同时检测2D 18个关键点
Implementation details
- DDPM https://nn.labml.ai/diffusion/ddpm/index.html
- DDIM https://huggingface.co/docs/diffusers/api/schedulers/ddim
Results




Conclusions
- 适合穿衣服的人,如果只有衣服就无法估计pose,不适用这种情况
- 在复杂pose下,garment warping和detail-preserving效果确实很好
Limitation
- leaking artifacts: 来自segentation和pose的误差
- 使用clothing-agnostic RGB 不够理想,因为有时候只能保留部分identity
- 数据集背景统一且干净,在复杂背景下效果没有实验
References
FiLM: Visual Reasoning with a General Conditioning Layer



