TERMINOLOGY
FLOPs
FLOPs:(部分大写,小s)floating point operations指的是浮点运算次数,理解为计算量,可以用来衡量算法/模型时间的复杂度。FLOPS:(全部大写,大s),Floating-point Operations Per Second,每秒所执行的浮点运算次数,理解为计算速度, 是一个衡量硬件性能/模型速度的指标,即一个芯片的算力。MACCs:multiply-accumulate operations,乘-加操作次数,MACCs大约是FLOPs的一半。将 w[0]∗x[0]+… 视为一个乘法累加或1个MACC。
MAC
MAC: Memory Access Cost 内存访问代价。指的是输入单个样本(一张图像),模型/卷积层完成一次前向传播所发生的内存交换总量,即模型的空间复杂度,单位是 Byte。
Bandwitdh
GPU的内存带宽决定了它将数据从内存 (vRAM) 移动到计算核心
(Tensor core)的速度,是比GPU内存速度更具代表性的指标。GPU的内存带宽的值取决于内存和计算核心之间的数据传输速度,以及这两个部分之间总线中单独并行链路的数量。
Latency and Throughput
- 延迟 (
Latency): 延迟是指提出请求与收到反应之间经过的时间,延迟都是以毫秒来计量的。(单位:ms) - 吞吐量 (
Throughput): 在一个时间单元(如:一秒)内网络能处理的最大输入样例数。(帧率FPS:samples/second)
CPU 是低延迟低吞吐量处理器;GPU 是高延迟高吞吐量处理器。
GPU Utility
本质只是反应了,在采样时间段内,一个或多个内核(kernel)在 GPU 上执行的时间百分比,采样时间段取值 1/6s~1s。
通俗来讲,就是,在一段时间范围内, GPU 内核运行的时间占总时间的比例。比如 GPU Util 是 69%,时间段是 1s,那么在过去的 1s 中内,GPU 内核运行的时间是 0.69s。如果 GPU Util 是 0%,则说明 GPU 没有被使用,处于空闲中。
NVIDIA GPU ARCH
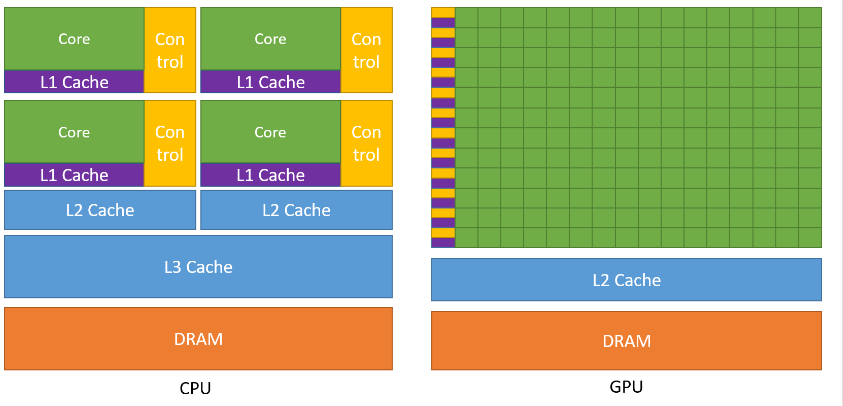
GPU 设计了更多的晶体管(transistors)用于数据处理(data process)而不是数据缓冲(data caching)和流控(flow control),因此 GPU 很适合做高度并行计算(highly parallel computations)。同时,GPU 提供比 CPU 更高的指令吞吐量和内存带宽(instruction throughput and memory bandwidth)。
高效 CNN 总结
网络宽度,即通道(channel)的数量,也是滤波器(3 维)的数量;网络深度,即 layer 的层数,如 resnet18 有 18 层网络。注意我们这里说的网络宽度和宽度学习一类的模型没有关系,而是特指深度卷积神经网络的(通道)宽度。
- 网络深度的意义:
CNN的网络层能够对输入图像数据进行逐层抽象,比如第一层学习到了图像边缘特征,第二层学习到了简单形状特征,第三层学习到了目标形状的特征。即深度决定了网络的表达(抽象)能力,网络越深学习能力越强。 - 网络宽度的意义:网络越宽,对目标特征的提取能力越强,即这一层网络能学习到更加丰富的特征,比如不同方向、不同频率的纹理特征等。即宽度决定了网络在某一层学到的信息量。
总而言之,在一定的程度上,网络越深越宽,性能越好,但关键在于如何取 trade-off。
结论
- 分析模型的推理性能得结合具体的推理平台(常见如:英伟达
GPU、移动端ARMCPU、端侧NPU芯片等);目前已知影响CNN模型推理性能的因素包括: 算子计算量FLOPs(参数量Params)、卷积block的内存访问代价(访存带宽)、网络并行度等。但相同硬件平台、相同网络架构条件下,FLOPs加速比与推理时间加速比成正比。 - 建议对于轻量级网络设计应该考虑直接
metric(例如速度speed),而不是间接metric(例如FLOPs)。 FLOPs低不等于latency低,尤其是在有加速功能的硬体 (GPU、DSP与TPU)上不成立,得结合具硬件架构具体分析。- 不同网络架构的
CNN模型,即使是FLOPs相同,但其MAC也可能差异巨大。 Depthwise卷积操作对于流水线型CPU、ARM等移动设备更友好,对于并行计算能力强的GPU和具有加速功能的硬件(专用硬件设计-NPU 芯片)上比较没有效率。Depthwise卷积算子实际上是使用了大量的低FLOPs、高数据读写量的操作。因为这些具有高数据读写量的操作,再加上多数时候GPU芯片算力的瓶颈在于访存带宽,使得模型把大量的时间浪费在了从显存中读写数据上,从而导致GPU的算力没有得到“充分利用”。结论来源知乎文章-FLOPs与模型推理速度和论文 G-GhostNet。
建议
- 在大多数的硬件上,
channel数为16的倍数比较有利高效计算。如海思351x系列芯片,当输入通道为4倍数和输出通道数为16倍数时,时间加速比会近似等于FLOPs加速比,有利于提供NNIE硬件计算利用率。(来源海思351X芯片文档和MobileDets论文) - 低
channel数的情况下 (如网路的前几层),在有加速功能的硬件使用普通convolution通常会比separable convolution有效率。(来源 MobileDets 论文) - shufflenetv2 论文 提出的四个高效网络设计的实用指导思想: G1同样大小的通道数可以最小化
MAC、G2-分组数太多的卷积会增加MAC、G3-网络碎片化会降低并行度、G4-逐元素的操作不可忽视。 GPU芯片上 3×3 卷积非常快,其计算密度(理论运算量除以所用时间)可达 1×1 和 5×5 卷积的四倍。(来源 RepVGG 论文)- 从解决梯度信息冗余问题入手,提高模型推理效率。比如 CSPNet 网络。
- 从解决
DenseNet的密集连接带来的高内存访问成本和能耗问题入手,如 VoVNet 网络,其由OSA(One-Shot Aggregation,一次聚合)模块组成。
模型部署总结
在阅读和理解经典的轻量级网络 mobilenet 系列、MobileDets、shufflenet 系列、cspnet、vovnet、repvgg 等论文的基础上,做了以下总结:
- 低算力设备-手机移动端
cpu硬件,考虑mobilenetv1(深度可分离卷机架构-低FLOPs)、低FLOPs和 低MAC的shuffletnetv2(channel_shuffle算子在推理框架上可能不支持) - 专用
asic硬件设备-npu芯片(地平线x3/x4等、海思3519、安霸cv22等),分类、目标检测问题考虑cspnet网络(减少重复梯度信息)、repvgg2(即RepOptimizer:vgg型直连架构、部署简单) - 英伟达
gpu硬件-t4芯片,考虑repvgg网络(类vgg卷积架构-高并行度有利于发挥gpu算力、单路架构省显存/内存,问题:INT8 PTQ掉点严重)
MobileNet block (深度可分离卷积 block, depthwise separable convolution block)在有加速功能的硬件(专用硬件设计-NPU 芯片)上比较没有效率。
显卡性能
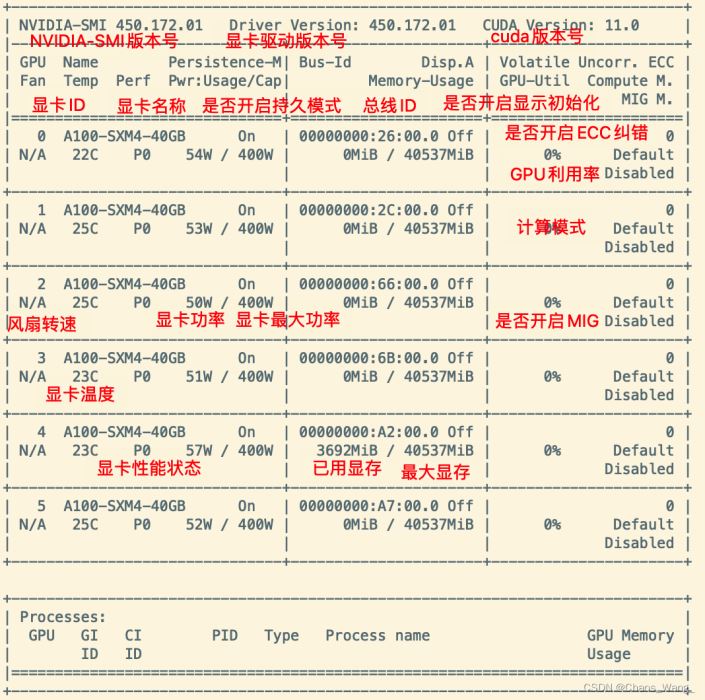
持久模式:persistence mode 能够让 GPU 更快响应任务,待机功耗增加。
关闭 persistence mode 同样能够启动任务。
持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少
风扇转速:主动散热的显卡一般会有这个参数,服务器显卡一般是被动散热,这个参数显示N/A。
从0到100%之间变动,这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能打不到显示的转速。
有的设备不会返回转速,因为它不依赖风扇冷却而是通过其他外设保持低温(比如有些实验室的服务器是常年放在空调房间里的)。
温度:单位是摄氏度。
性能状态:从P0到P12,P0表示最大性能,P12表示状态最小性能。
Disp.A:Display Active,表示GPU的显示是否初始化。
ECC纠错:这个只有近几年的显卡才具有这个功能,老版显卡不具备这个功能。
MIG:Multi-Instance GPU,多实例显卡技术,支持将一张显卡划分成多张显卡使用,目前只支持安培架构显卡。
新的多实例GPU (MIG)特性允许GPU(从NVIDIA安培架构开始)被安全地划分为多达7个独立的GPU实例。
用于CUDA应用,为多个用户提供独立的GPU资源,以实现最佳的GPU利用率。
对于GPU计算能力未完全饱和的工作负载,该特性尤其有益,因此用户可能希望并行运行不同的工作负载,以最大化利用率。RTX4090,24GB显存,大概1.5W人民币;
A100,40GB显存,大概5.5W人民币;
A100,80GB显存,大概7.5W人民币;
H100,80GB显存,大概24W人民币;
单机多卡
PCIE通信的情况下(rtx4090显卡情况),单卡性能为基准100%,那么双卡的性能可能是(100%+90%),三卡可能是(100%+90%+80%),以此类推,8卡可能是(100%+90%+80%+70%+60%+50%+40%+30%),也就是说使用PCIE通信的情况下单机多卡的加速比要远低于线性加速比。
如果使用nvlink通信(A100和H100显卡情况),单卡性能为基准100%,那么双卡的性能可能是(100%+98%),三卡可能是(100%+98%+96%),以此类推,8卡可能是(100%+98%+96%+94%+92%+90%+88%+86%),所以说单机多卡的情况下nvlink通信也会较大幅度提供性能。
$ nvidia-smi topo --matrix #查看系统/GPU 拓扑
$ nvidia-smi nvlink --status #查询 NVLink 连接本身以确保状态、功能和运行状况。
$ nvidia-smi nvlink --capabilities #查询 NVLink 连接本身以确保状态、功能和运行状况。$ nvidia-smi topo --matrix
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X SYS 0,2,4,6,8,10 0
GPU1 SYS X 1,3,5,7,9,11 1
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
$ nvidia-smi nvlink --status
GPU 0: NVIDIA A100 80GB PCIe (UUID: GPU-e940fdff-7348-576b-fa77-4ce0f23dac70)
Link 0: <inactive>
Link 1: <inactive>
Link 2: <inactive>
Link 3: <inactive>
Link 4: <inactive>
Link 5: <inactive>
Link 6: <inactive>
Link 7: <inactive>
Link 8: <inactive>
Link 9: <inactive>
Link 10: <inactive>
Link 11: <inactive>
GPU 1: NVIDIA A100 80GB PCIe (UUID: GPU-1bf9bc37-b6aa-f94a-56b3-02cc34601dae)
Link 0: <inactive>
Link 1: <inactive>
Link 2: <inactive>
Link 3: <inactive>
Link 4: <inactive>
Link 5: <inactive>
Link 6: <inactive>
Link 7: <inactive>
Link 8: <inactive>
Link 9: <inactive>
Link 10: <inactive>
Link 11: <inactive>多机多卡
单机的基准性能为100%,双机性能(100%+90%),三机性能(100%+90%+90%),四机性能(100%+90%+90%+90%),五机性能(100%+90%+90%+90%+80%)等。



