Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models

Abstract
- 文本提示难以实现细节控制,即使文本很长很复杂
- Uni-ControlNet同时利用局部控制(图像条件)和全局控制(图像字符嵌入),且只需要在冻结的预训练模型上微调2个适配器,就能将多个图像控制条件融入到一个模型中
- text-to-image (T2I)
Contributions
- 将所有条件分成两组——局部条件和全局条件,每组条件设计一个适配器Adapter,一共2个适配器,不需要联合训练,采用分开训练
- 局部控制:引入了一种多尺度条件注入策略,使用共享的局部条件编码器适配器。该适配器首先将局部控制信号转换为调制信号,然后用于调制输入的噪声特征。
- 全局控制:使用另一个共享全局条件编码器将其转换为条件标记,然后将其与文本标记连接起来形成扩展提示,并通过交叉注意与输入特征进行交互

Related Work
Controllable Diffusion Models
- ControlNet
- T2I-Adapter
每个条件单独一个适配器模型,非统一
Methodology
Overview
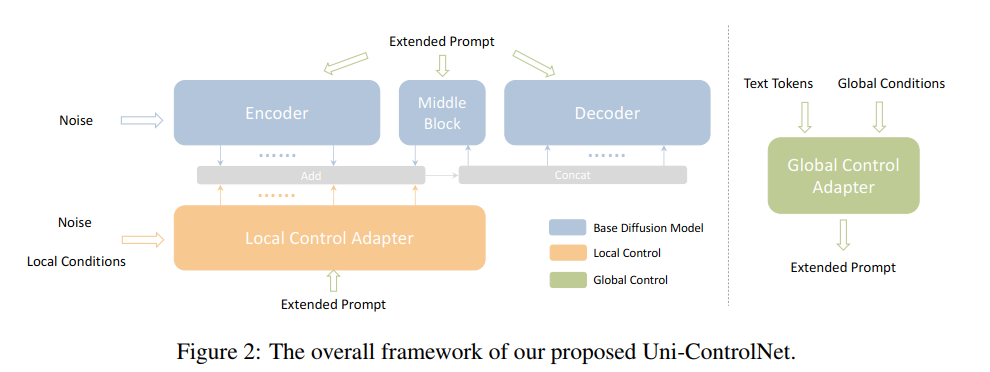
Local Control Adapter
- 受ControlNet启发,固定了SD模型的权重且复制了其encoder和middle block的结构和权重分别为F‘,M’,然后修改了SD的decoder的输入,使其包含局部控制信息,具体如下:
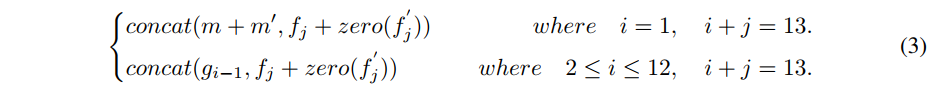
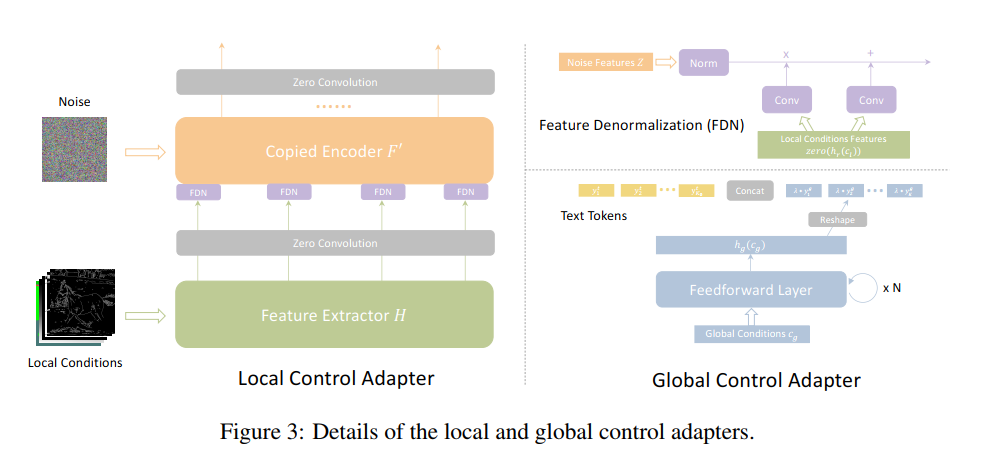
- 和ControlNet不同地方是,没有直接将条件和噪声输入相加,而是采用多尺度条件注入策略
- 将不同的局部条件沿着通道维度进行拼接 Cl
- 使用堆叠的卷积层构成的特征提取器H提取不同尺度的特征图,64 32 16 8
- 受SPADE启发,实现了特征去正则化FDN,使用条件特征来调制归一化的输入噪声特征

上面就是将不同尺度的噪声和特征进行相加,2个学习参数分别学习空间敏感的尺度和偏移调制
zero是零卷积
调制采用乘法,直接和噪声相乘
注意:局部图像条件没有用CLIP,而是用CNN提取特征,ControlNet就是采用CLIP提取image token embeddings
Global Control Adapter
- 使用CLIP提取一个图像全局条件的token嵌入
- 将全局控制信号用条件编码器hg投影到条件嵌入空间(条件编码器是由前馈层堆叠,可以将文本嵌入和图像条件嵌入对其到嵌入空间)
- reshape条件嵌入成K个全局字符,默认是4个
- 将K和文本字符K0相加,构成扩展提示(总的字符数是K+K0)
- 扩展提示字符作为所有交叉注意力层(包括SD模型和控制适配器)的输入

Experiments
Training Strategy
- 2个适配器分开训练(单独训练全局控制,单独训练局部控制,没有先后)
- 以一定概率随机丢弃每一个条件
- 以一定概率保留或丢弃全部条件
- 推理时候直接组合,不需要联合训练
Results


Conclusions
- 只需要2个适配器即可
- 容易部署



