T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models

Abstract
- T2I 模型可以学习复杂的结构和有意义的语义
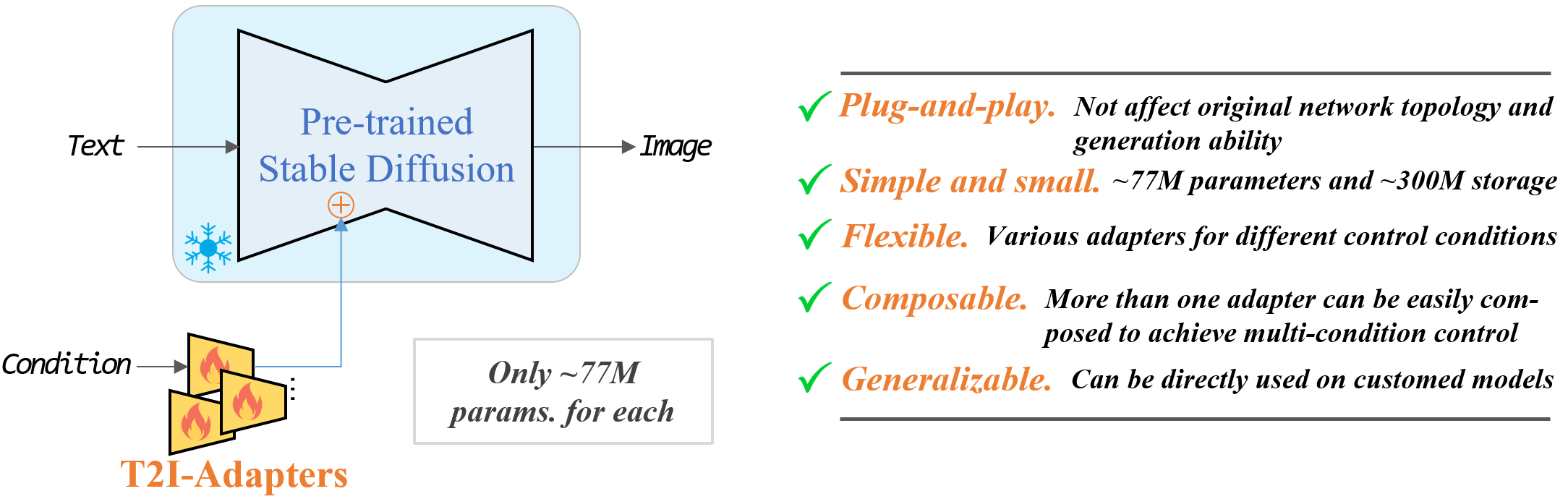
- T2I-Adapters 将T2I内部知识和外部控制信号进行对齐,且冻结T2I模型参数
Contributions
- 灵活性:不同控制条件(空间颜色控制和复杂结构控制)训练不同的适配器
- 可组合:将多个适配器组合实现多个条件同时控制
- 泛化性:T2I是冻结的,只需要对适配器进行微调
- 轻量化:77M params参数量,300M storage存储量
Related Work
Adapter
- 起源于NLP,对大模型微调效率很低,所以提出用适配器进行transfer,只需要针对特定任务设计适配器,更好的将大模型应用到下游任务中
- ViT-Adapter
Methodology
Overview
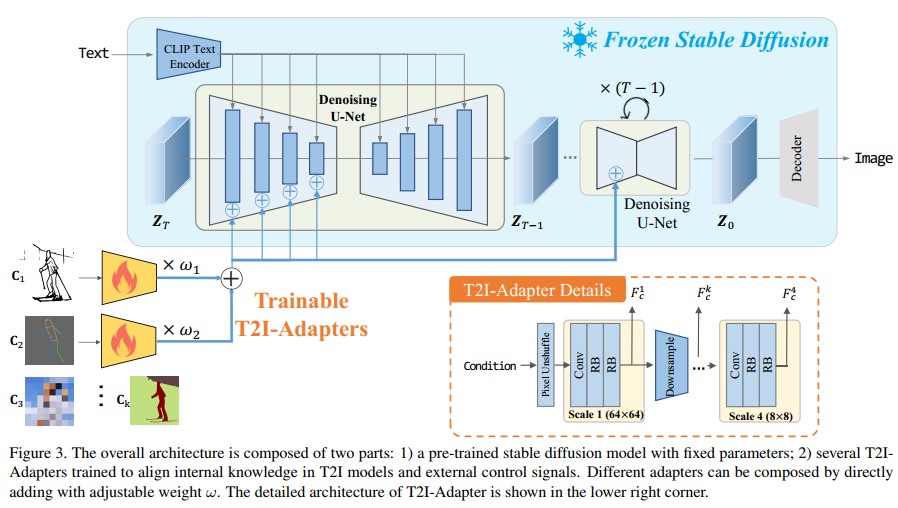
Adapter Design
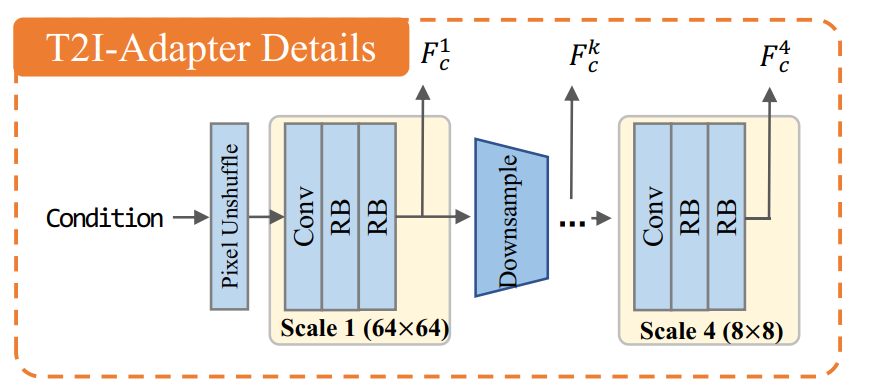
- 输入图像512X512,通过
pixel unshuffle下采样到64X64 - 4个特征提取块 + 3个下采样块 = 多尺度特征
- 特征提取block=1个Conv+2个residual blocks
- 下采样块
Structure controlling
- sketch, depth map, semantic segmentation map, and keypose
Spatial color palette
- hue and spatial distribution
- 使用bicubic下采样去除图像语义和结构信息,同时保留足够的color信息
- 使用nearest上采样恢复图像原始尺寸color map
- 用获取的color map作为条件进行训练
- color map

Multi-adapter controlling
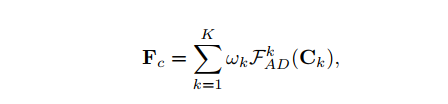
- 不需要重新训练,只需要将每个条件的适配器进行线性组合即可,自定义权重,从而实现多个条件以不同权重进行共同控制

Experiments



Conclusions
- 鸡肋



