Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
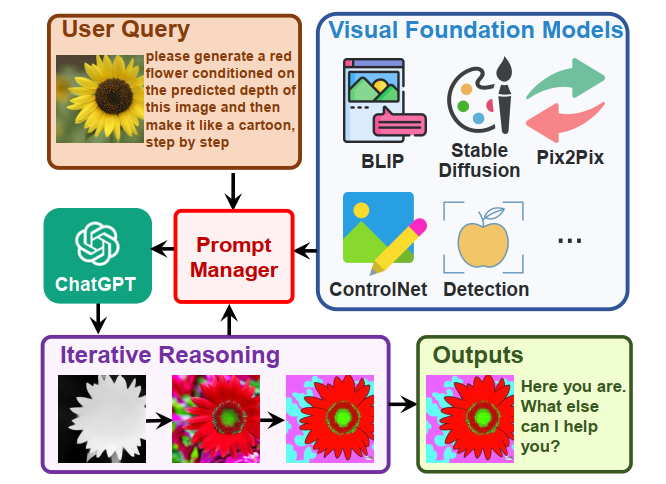
Abstract
- TaskMatrix connects ChatGPT and a series of Visual Foundation Models to enable sending and receiving images during chatting.
- 核心是Prompts manager,能够让chatGPT理解visual tasks prompts,然后根据prompts来调用相关的视觉模型进行任务处理
Contributions
- Prompts manager
Related Work
- VAQ 视觉任务的问答对 (visual question-answer pairs )
Methodology
Overview
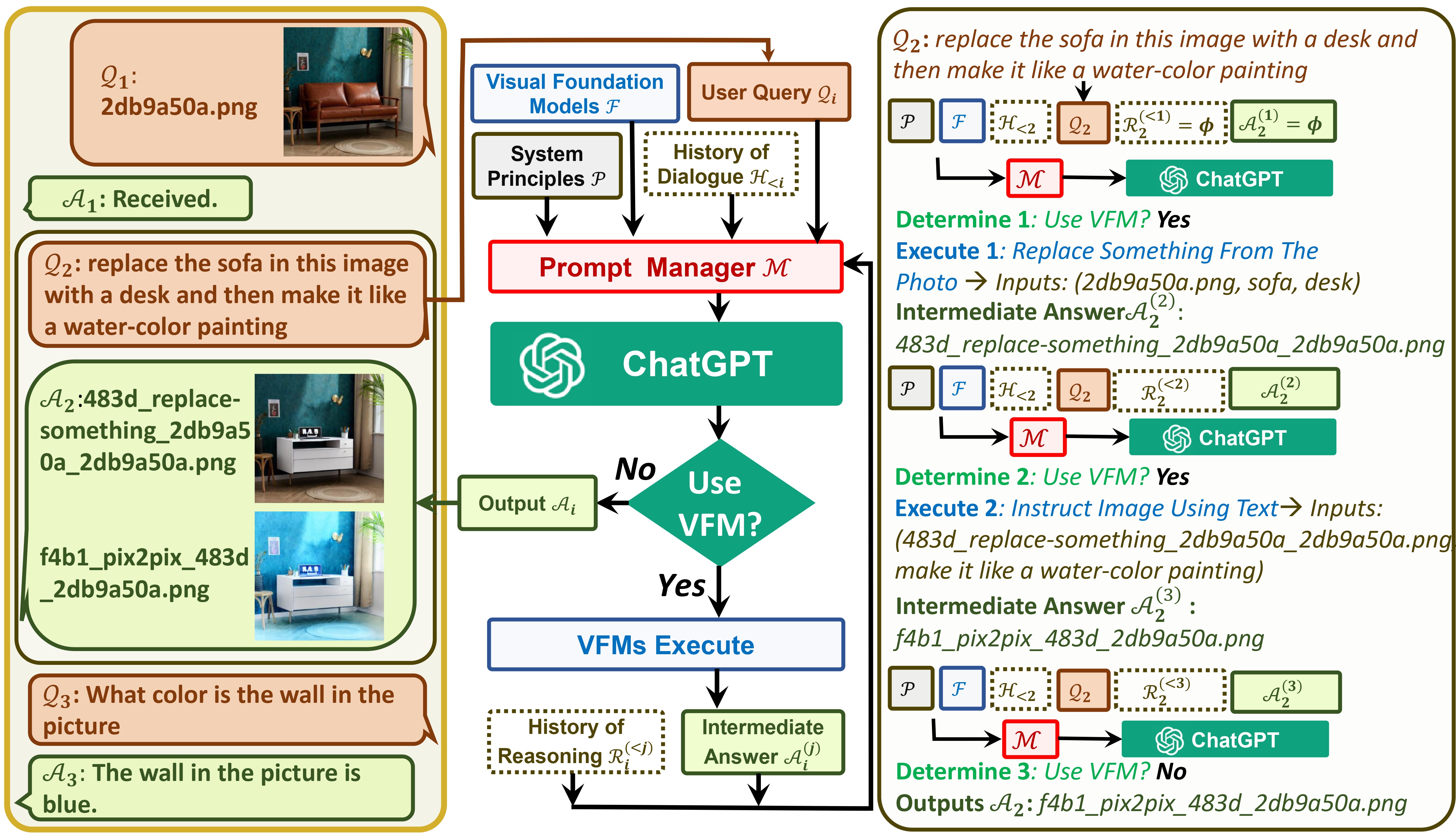
Prompts manager
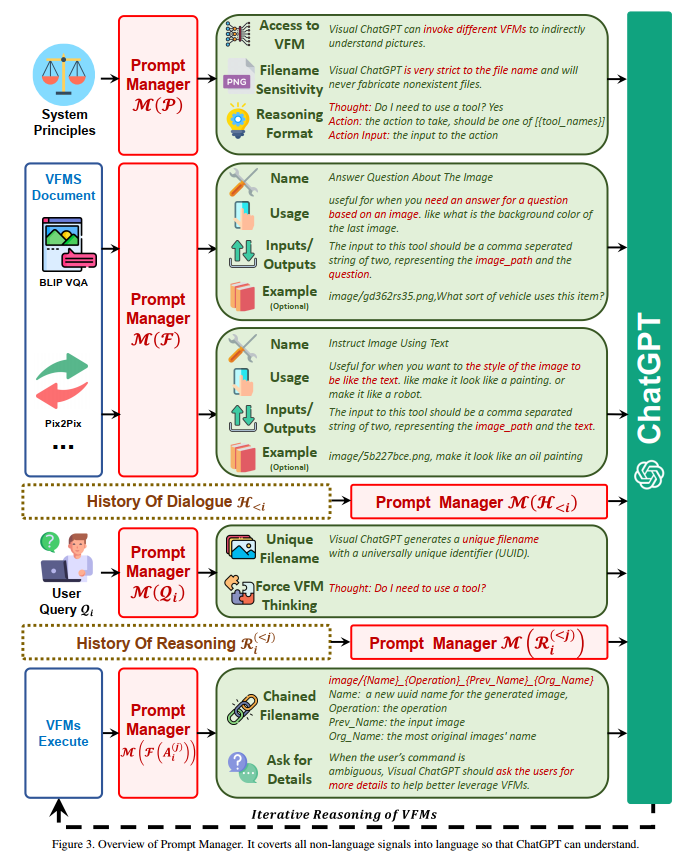
Visual foundation models
Here we list the GPU memory usage of each visual foundation model, you can specify which one you like:
| Foundation Model | GPU Memory (MB) |
|---|---|
| ImageEditing | 3981 |
| InstructPix2Pix | 2827 |
| Text2Image | 3385 |
| ImageCaptioning | 1209 |
| Image2Canny | 0 |
| CannyText2Image | 3531 |
| Image2Line | 0 |
| LineText2Image | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2Scribble | 0 |
| ScribbleText2Image | 3531 |
| Image2Pose | 0 |
| PoseText2Image | 3529 |
| Image2Seg | 919 |
| SegText2Image | 3529 |
| Image2Depth | 0 |
| DepthText2Image | 3531 |
| Image2Normal | 0 |
| NormalText2Image | 3529 |
| VisualQuestionAnswering | 1495 |
Experiments
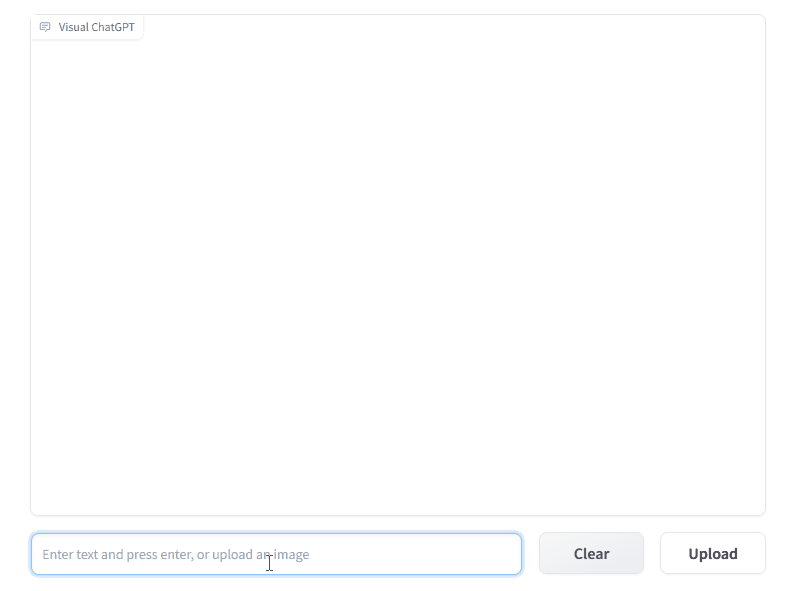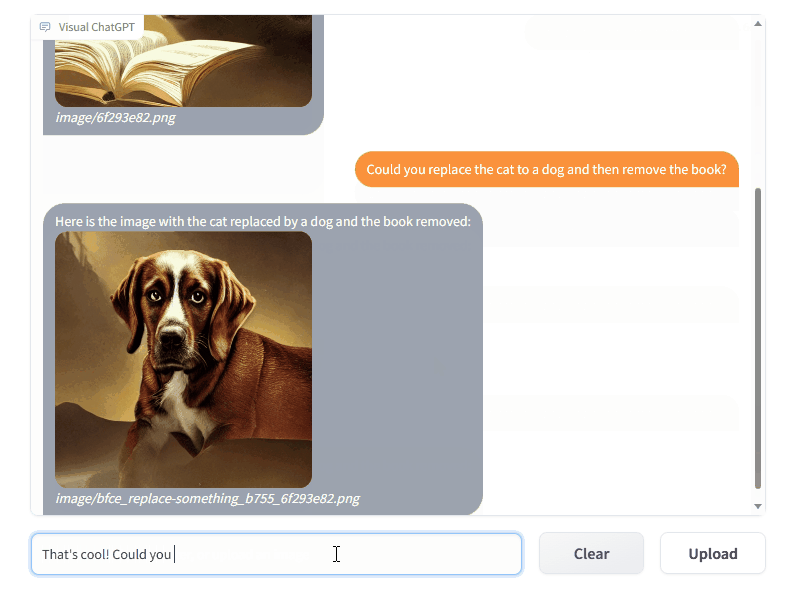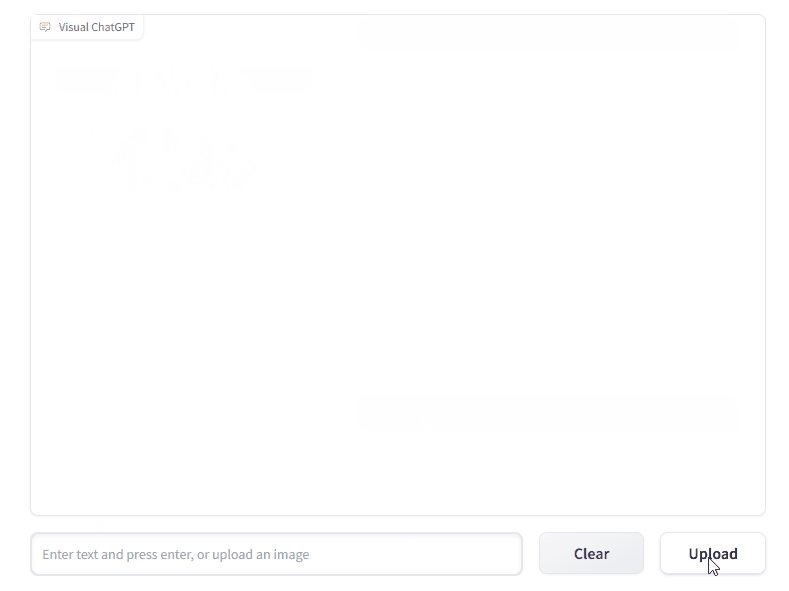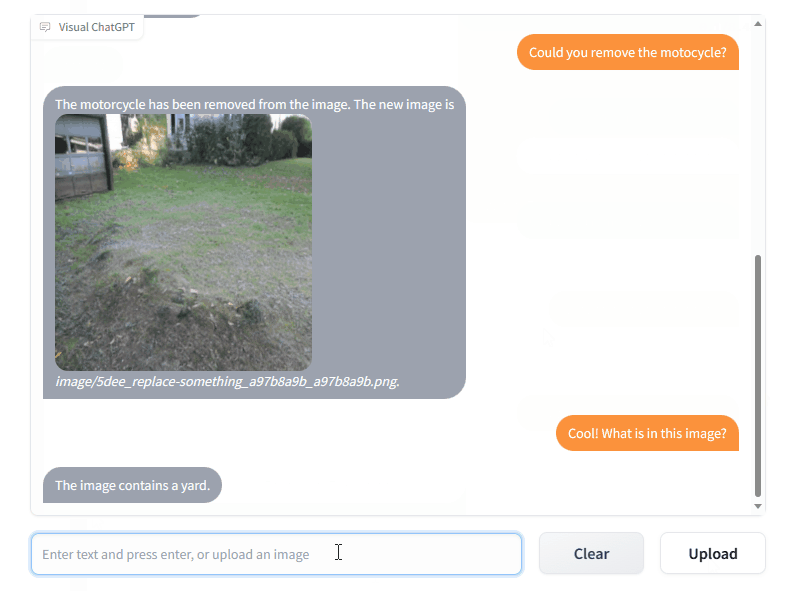
Quick Start
# clone the repo
git clone https://github.com/microsoft/TaskMatrix.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
pip install git+https://github.com/IDEA-Research/GroundingDINO.git
pip install git+https://github.com/facebookresearch/segment-anything.git
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start TaskMatrix !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are separated by underline '_', the different models are separated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,
Inpainting_cuda:0,ImageCaptioning_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
Conclusions
- 需要OpenAI的ChatGPT的API KEY
- 用问答的方式处理视觉任务,比如检测、分割等
- 支持cpu gpu,根据memory加载合适的visual models
References
You can find your Secret API key in your User settings.
Check out our Best Practices for API Key Safety to learn how you can keep your API key protected.



