MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
Abstract
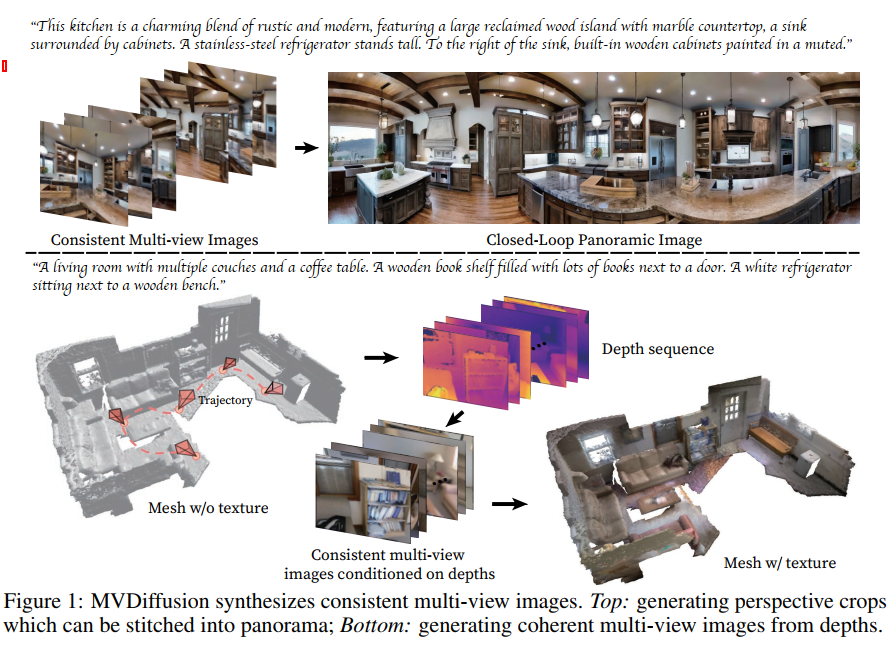
- 全景图生成:输入文本提示或者文本图像条件,生成8个视角关联的图像,即可拼接成一张全景图 panaroma
- 多视角深度图生成纹理网格:通过深度图生成 3D geometry mesh with texture
Contributions
- 根据文本描述,MVDiffusion 可生成具有高分辨率和丰富内容的整体一致的多视角图像,这对全景生成和多视角深度图像生成等实际任务大有裨益。
Related Work
Image generation
3D content generation
Methodology
Overview
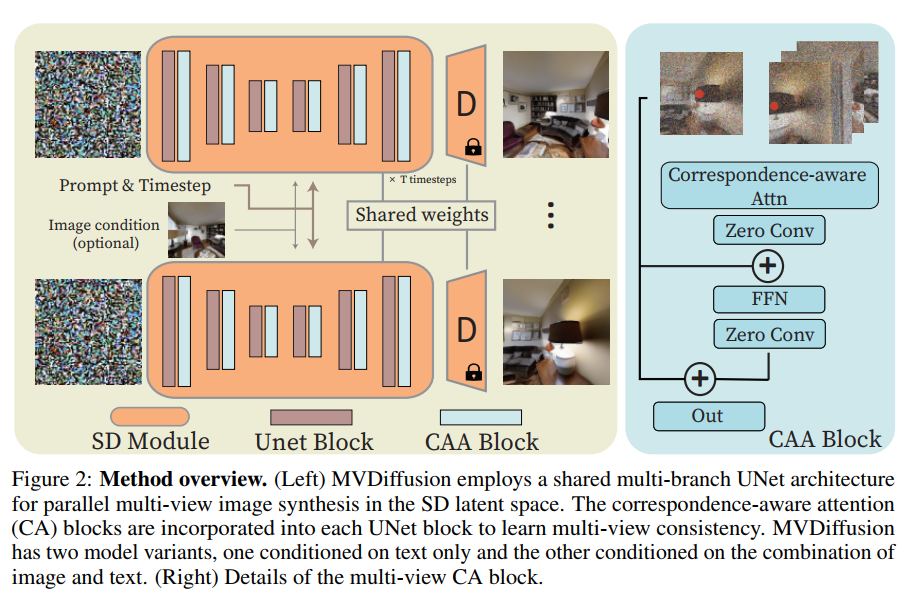
Text-conditioned generation model
- 8个视角需要8个文本提示
- 每张图像的latents初始化为独立的高斯噪声
- 在去噪步,每个隐层噪声喂给多分支的UNet
- 最后通过SD的VAE Decoder解码成多视角图像
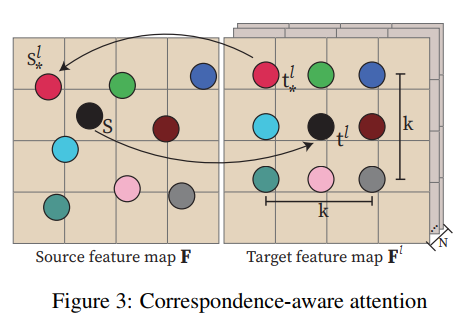
Correspondence-aware Attention
- 目的是加强多视角特征图的连续性 consistency
- 借鉴ControlNet,用零卷积初始化为0
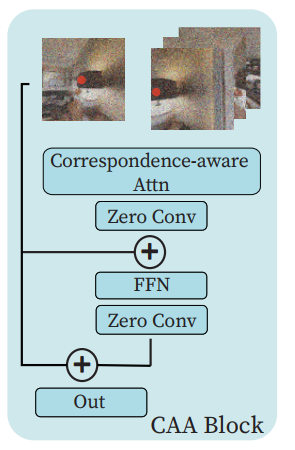
Source和Target的匹配点问题
- 定义了KXK的领域限制,一般K=3或者K=1效率比较高
- 位置坐标不是整数,而是通过双线性插值得到的浮点数
- l是第l个视角 l属于[0,N]
- 计算采用CA标准计算 WQ, WK, and WV are the learnable weights
of query, key and value matrices
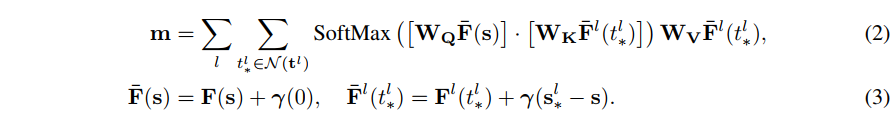
- 最关键是:将S和S*的位置差分增加到position encoding
γ(),因为位移提供了局部邻域的相对位置
Image&text-conditioned generation model
- Image&text-conditioned generation model
- 1个条件图,生成7个目标图像即可
- SD的inpainting model作为base model,再加上CAA

- Multi-view depth-to-image generation
- 从深度图中提取关键帧key-frame
- 通过给定相机pose和帧外插生成图像

Experiments
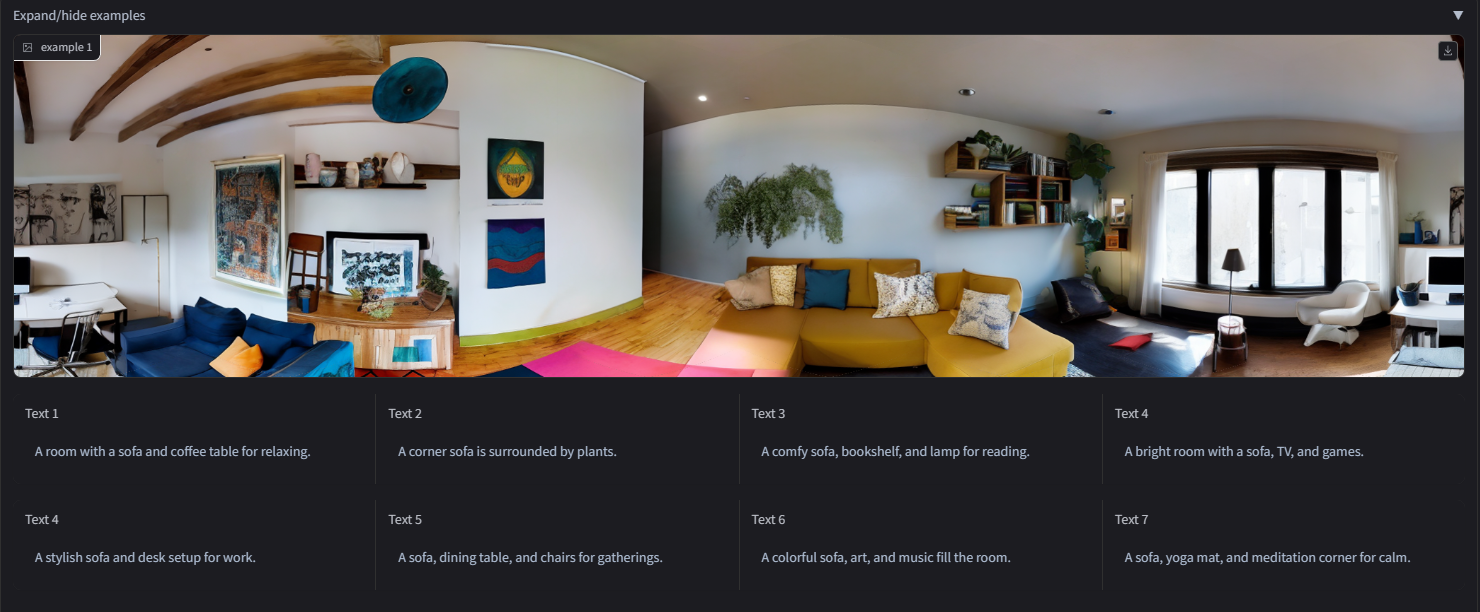
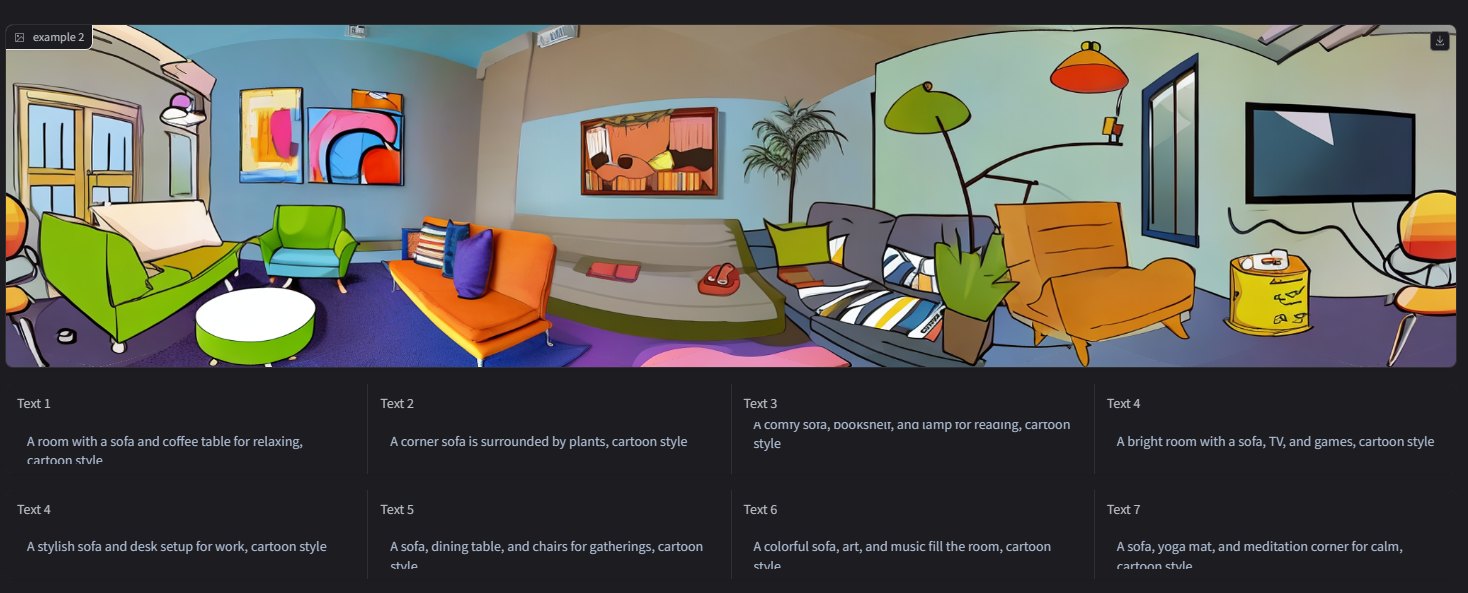
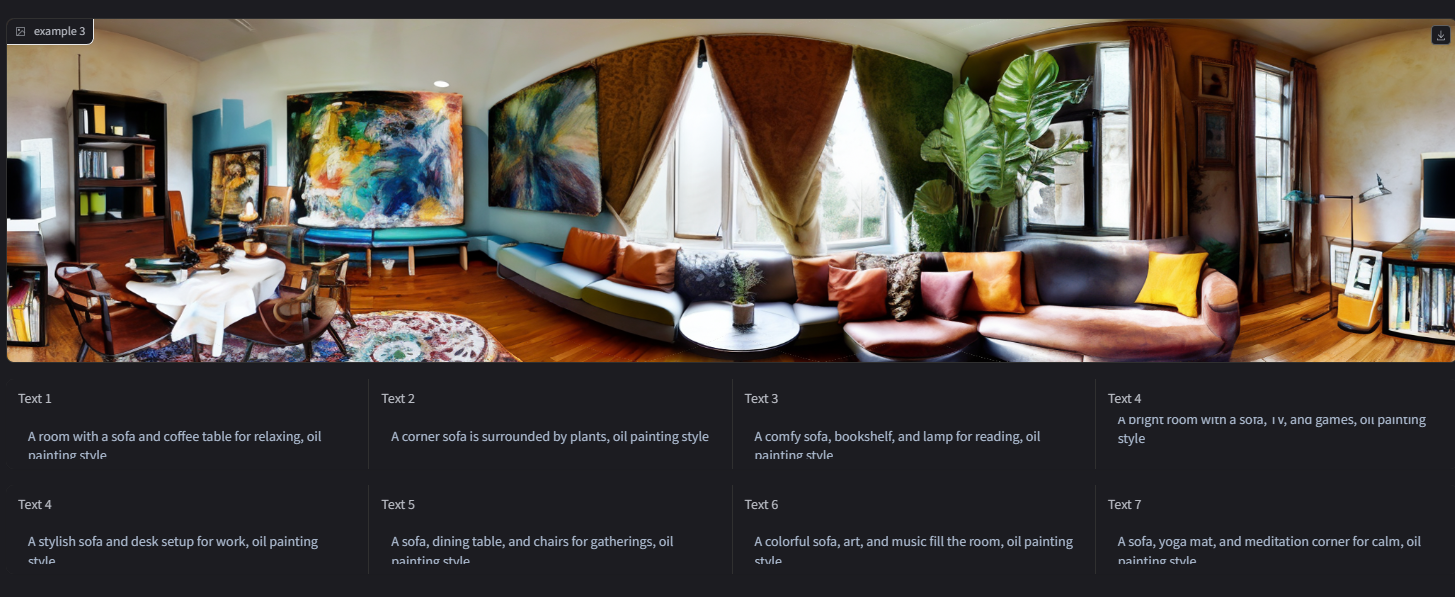
- 全景图

- 深度图

Demos
- 布局明确
- 卡通风格 cartoon
- 油画风格 oil painting
Conclusions
- 引入了
CAA匹配点感知注意力机制 将多视角图像生成的连续性进行了强关联(匹配点) - 在建筑、室内设计行业,可以通过文本和图像条件直接生成全景图和3D室内模型,大大简化图纸设计工作,而且在家具布局layout和风格style上具有较好的生成表现



