An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion

Abstract
- 如何实现创作自由,现在只需要
3-5张用户提供的概念图像,可以是某一类物体,亦或是某一种风格,就可以在冻结的文生图模型的嵌入空间中学习一种新的关键词(也就是创造了一种新的且和图像对应的提示词prompt)
Contributions
- personalized text-to-image generation: T2I私人化 定制化 (特定的对象或者风格)
- Textual Inversions: 文本反演 (找到图像对应的pseudo伪关键词)
- GAN Inversion: 根据 GAN 启发的反演技术分析了嵌入空间,并证明它在失真和可编辑性之间也有权衡 (可以编辑生成图像)
Related Work
- Text-guided synthesis
- GAN inversion
- Diffusion-based inversion
- diffusion本省包括加噪声和去噪声的步骤,是一种inversion的方法
- 但是先前的方法,都是将给定的图像反演到模型潜在空间
- 然而本文是将用户提供的图像概念进行反演,并且将图像概念作为新的提示词,可以用于图像生成和编辑
- Personalization
Methodology
Overview
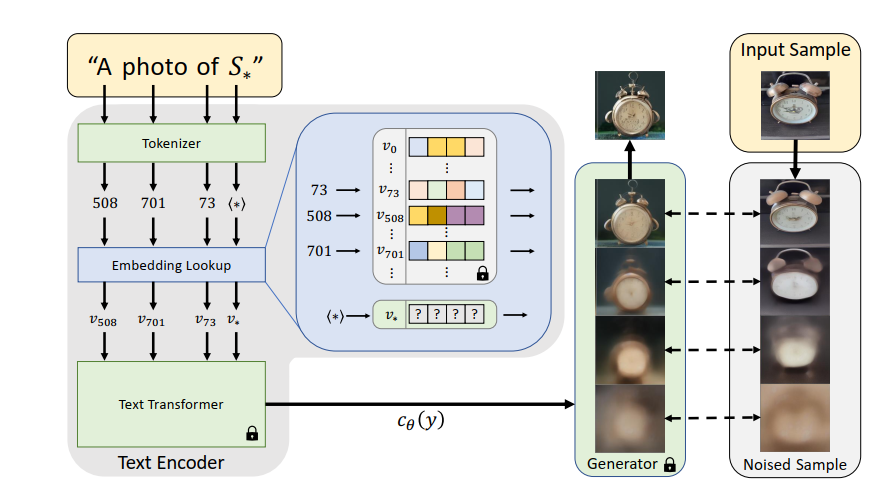
- 文本嵌入和反演过程概述 包含占位词的字符串首先被转换成标记(即字典中的单词或子单词索引)。这些标记被转换为连续向量表示(”嵌入”,v)。最后,嵌入向量被转换成一个单一的条件代码 cθ(y),用于指导生成模型。我们优化嵌入向量 v与我们的伪词 S∗ 相关联,使用重构目标。
Latent Diffusion Models
- 基于LDMs
Text embeddings
- 定义了占位符字符串 S*, 作为希望学习的新概念
- 我们干预嵌入过程并用学习到的新嵌入 v∗ 替换与标记化字符串相关的向量,实质上是将概念 “注入 “到我们的词汇中。这样,我们就可以像处理任何概念一样,将包含该概念的新句子概念的新句子,就像使用其他词一样
Textual inversion
- 为找到这些新的嵌入,我们使用了一小组图像(通常为 3-5 张),这些图像在不同的背景或姿势等多种环境中描述了我们的目标概念。我们通过直接优化的方式找到 v∗,具体做法是从小幅图像中采样,最小化 LDM 损失
- keeping both cθ and θ fixed.
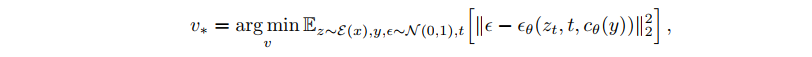
作为生成条件,我们从 CLIP ImageNet 模板。这些文本包含 “A photo of S∗”、”A rendition of S∗ “等形式
的提示等。
值得注意的是,这是一项重建任务。因此,我们希望它能促使学习到的嵌入技术捕捉构想中独有的精细视觉细节。
Experiments
- Image variations
A photo of S*生成S*图像

- Text-guided synthesis
with S*生成S*和其他提示词合成的图像

- Style transfer
in the style of S*

- Image curation 给定mask,替换成S*

- prompt templates
Below we provide the list of text templates used when optimizing a pseudo-word:
• “a photo of a S∗.”,
• “a rendering of a S∗.”,
• “a cropped photo of the S∗.”,
• “the photo of a S∗.”,
• “a photo of a clean S∗.”,
• “a photo of a dirty S∗.”,
• “a dark photo of the S∗.”,
• “a photo of my S∗.”,
• “a photo of the cool S∗.”,
• “a close-up photo of a S∗.”,
• “a bright photo of the S∗.”,
• “a cropped photo of a S∗.”,
• “a photo of the S∗.”,
• “a good photo of the S∗.”,
• “a photo of one S∗.”,
• “a close-up photo of the S∗.”,
• “a rendition of the S∗.”,
• “a photo of the clean S∗.”,
• “a rendition of a S∗.”,
• “a photo of a nice S∗.”,
• “a good photo of a S∗.”,
• “a photo of the nice S∗.”,
• “a photo of the small S∗.”,
• “a photo of the weird S∗.”,
• “a photo of the large S∗.”,
• “a photo of a cool S∗.”,
• “a photo of a small S∗.”Conclusions
- 用户提供的3-5张图像需要是同一对象不同的姿态或者背景
- 核心是给用户的图像加噪声,然后让网络重构噪声图像,这样就能建立映射关系(S*和图像)
- 用S*表示某一类对象或者风格,使用的提示词为
A photo of S*生成S*图像xxx S* xxx生成S*和其它合成的图像in the style of S*生成S*风格的图像mask替换S* (图像编辑)



