⚡ TextDiffuser-2 | 图像加logo神器
本文主要介绍用于 TextDiffuser-2 的应用,即用户输入文本描述,即可生成指定文本logo的图像。


👀 目录
[TOC]
1️⃣ 方法论
我们提出 TextDiffuser-2,旨在释放语言模型用于文本渲染的力量。具体来说,我们将语言模型驯化为布局规划器,以使用标题-OCR 对将用户提示转换为布局。该语言模型通过从用户提示中推断关键字或合并用户指定的关键字来确定其位置来展示灵活性和自动化。其次,我们利用扩散模型中的语言模型作为布局编码器来表示行级别文本的位置和内容。这种方法使扩散模型能够生成具有更广泛多样性的文本图像。
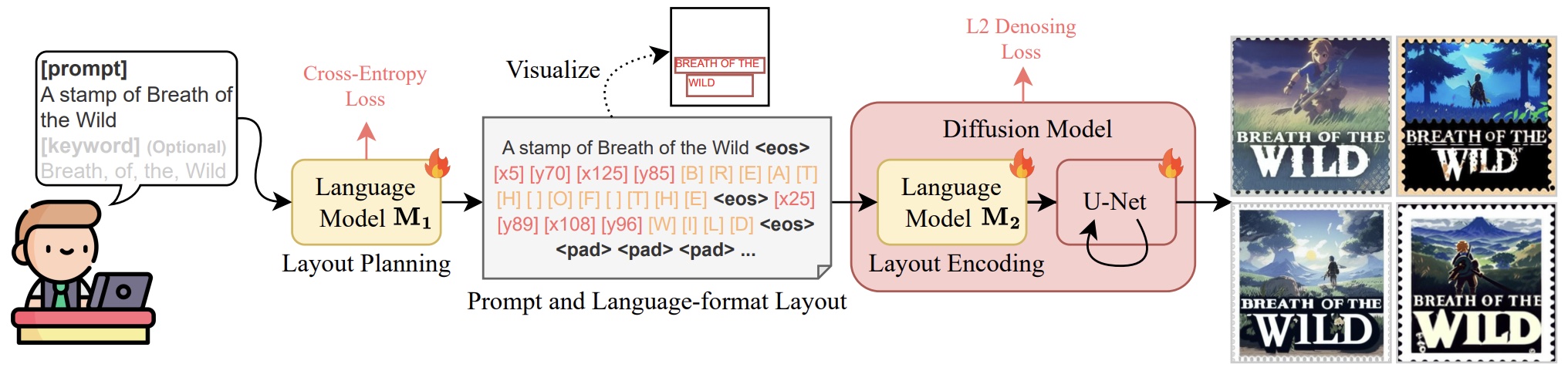
TextDiffuser-2 的架构
- 语言模型M1和扩散模型分两个阶段进行训练。语言模型M1可以将用户提示转换为语言格式的布局,并且还允许用户选择性地指定关键字。此外,提示和语言格式布局利用扩散模型内的可训练语言模型M2进行编码以生成图像。 M1在第一阶段通过交叉熵损失进行训练,而M2和U-Net在第二阶段使用去噪L2损失进行训练。
2️⃣ 效果对比
1 与现有方法相比文本到图像结果的可视化
- TextDiffuser-2可以自动从提示中提取关键字以进行准确渲染。此外,TextDiffuser-2 生成的字体表现出广泛的多样性。

2 在同一提示下生成多个图像的多样性的可视化
- TextDiffuser-2 能够生成更具艺术性的字体,增加字符位置和文本行倾斜角度的多样性。

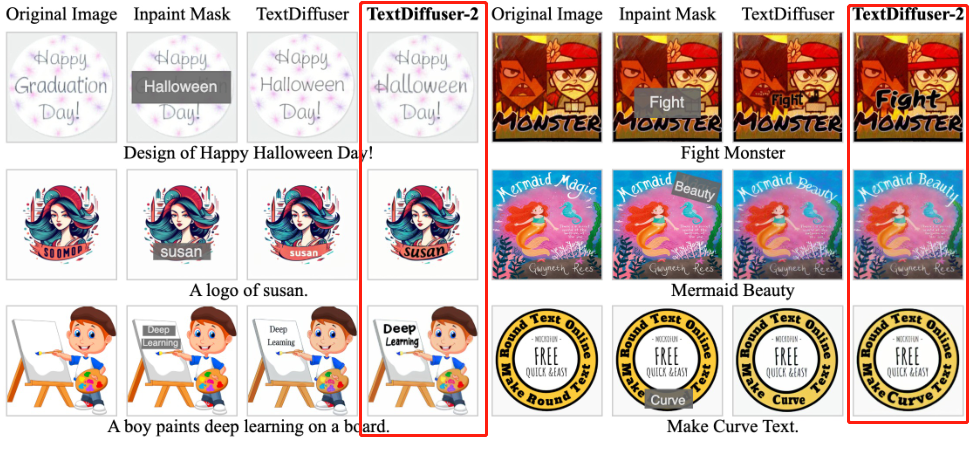
3 文本修复任务与TextDiffuser可视化比较
- TextDiffuser-2 可以生成更连贯的文本
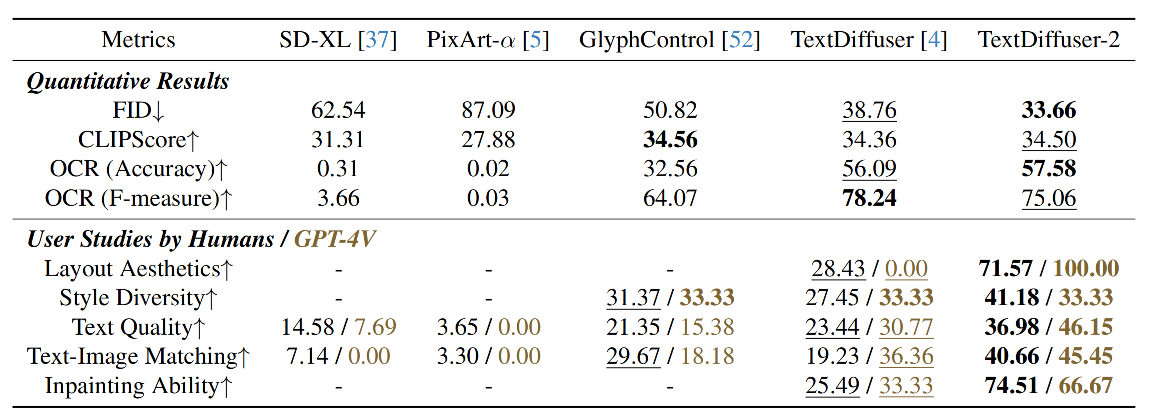
4 定量结果和用户研究的演示
- 我们还将 GPT-4V 纳入用户研究中。最好和第二好的结果以粗体和下划线的形式表示。 TextDiffuser-2 在大多数指标下取得了最佳结果。
3️⃣ 美图秀儿



- The words ‘KFC Plus’ are inscribed upon the wall in a neon light effect

- portrait of a ‘dragon’, concept art, sumi - e style, intricate linework, green smoke, artstation, trending, highly detailed, smooth, focus, art by yoji shinkawa,

- ‘iResearch666’ hat

- Thanksgiving ‘iResearch666’ Mens T Shirt

4️⃣ 免费测试
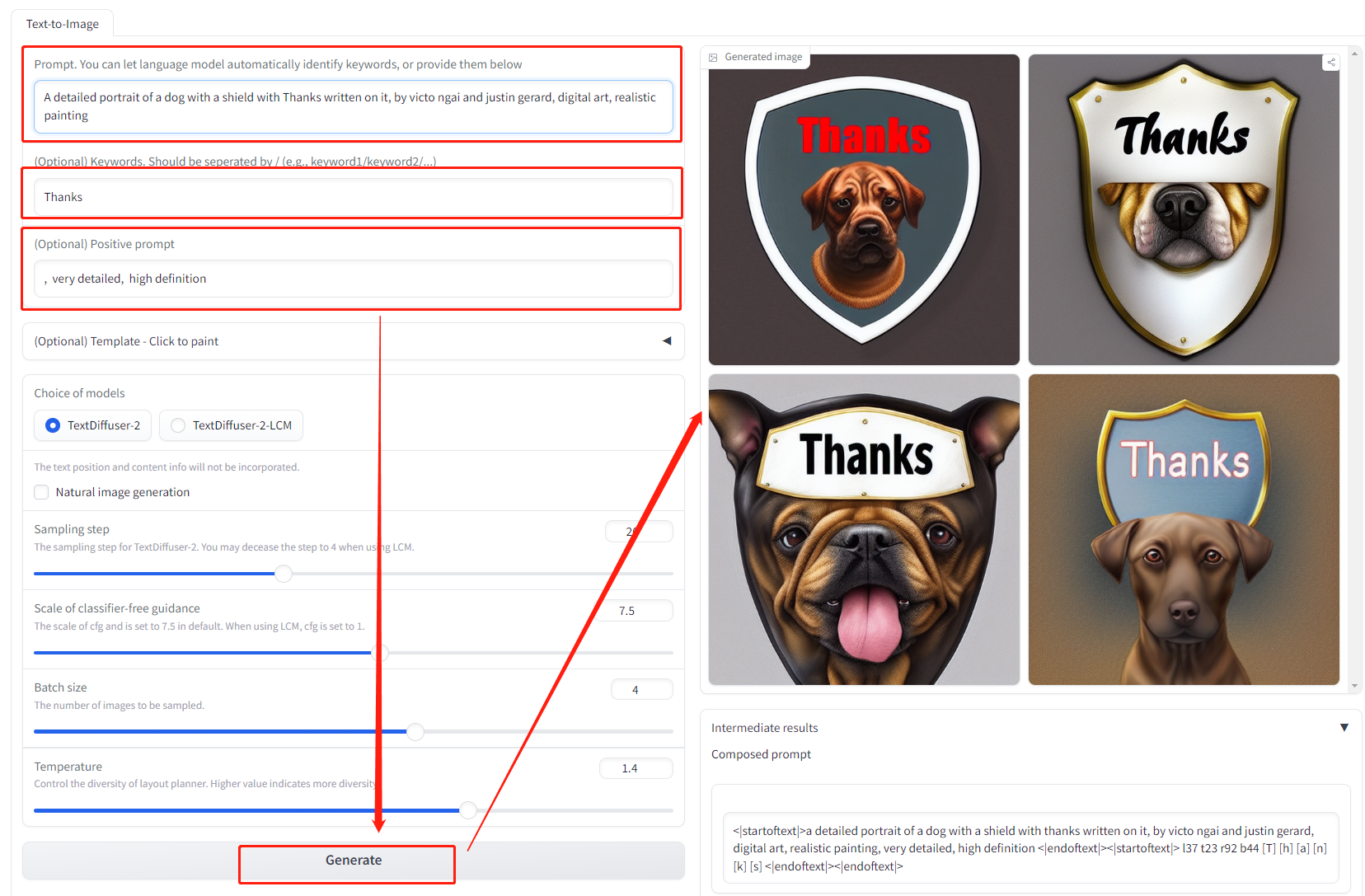
- 提示词
A detailed portrait of a dog with a shield with Thanks written on it, by victo ngai and justin gerard, digital art, realistic painting
- 生成图像
✅ 论文 https://arxiv.org/abs/2311.16465
✅ 代码 https://github.com/microsoft/unilm/tree/master/textdiffuser-2
✅ 测试
👉 https://huggingface.co/spaces/JingyeChen22/TextDiffuser-2
👉 https://huggingface.co/spaces/JingyeChen22/TextDiffuser
🤝 Thank you
❤️ 每周免费分享CV&AIGC相关最新资讯,感兴趣可以关注,喜欢动动小手点个赞,谢谢支持!
 |
 |
|---|



