本文介绍基于Diffusion虚拟试衣应用,即用户只需要上传一张单人照片和一张衣服照片,就能实现人穿衣服效果图像。
虚拟试穿技术允许用户在线上购物时预览服装在自己身上的效果,从而提高购物体验并减少退货率。

[TOC]
先睹为快


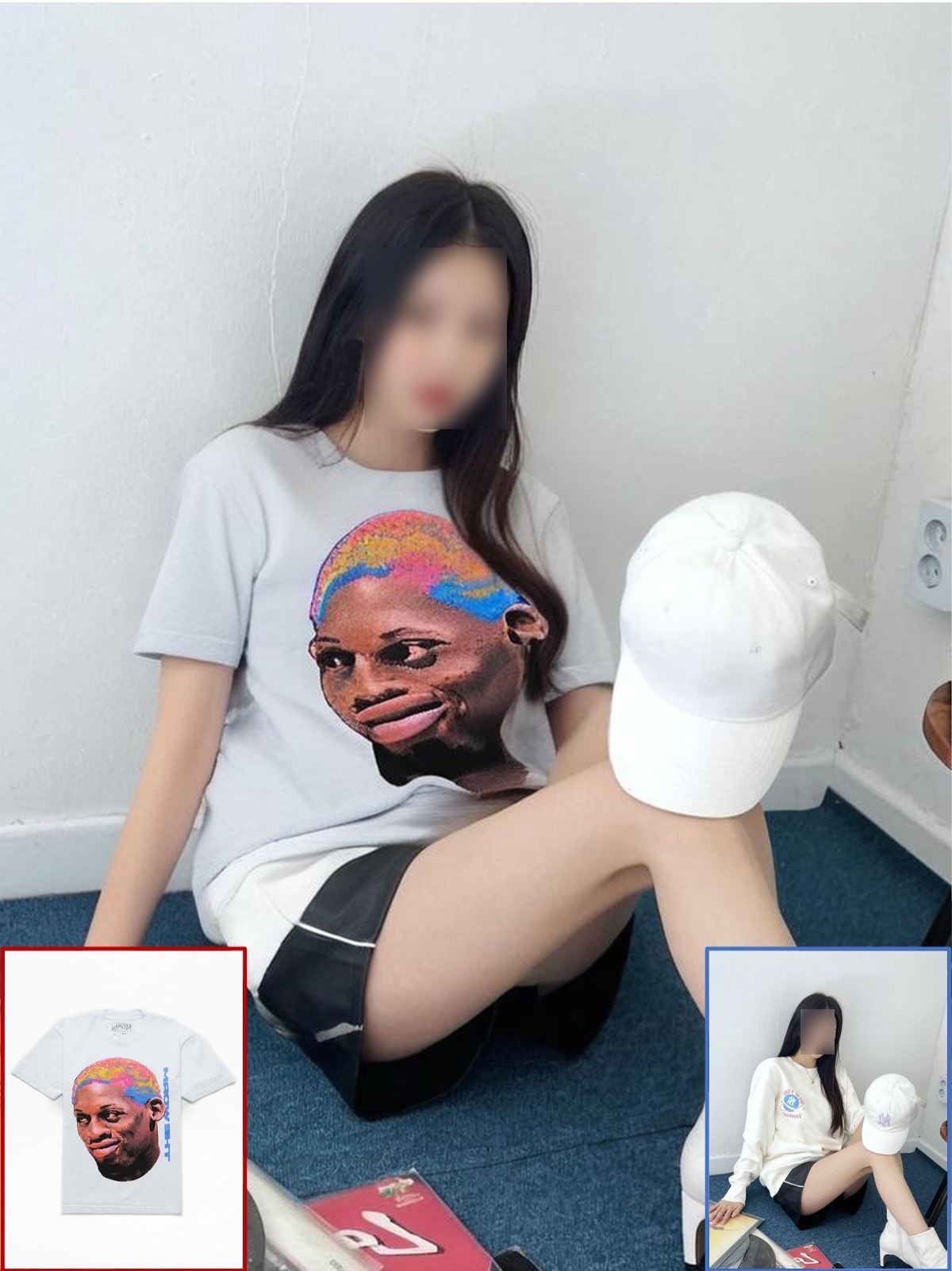

01 多人穿着同一件衣服
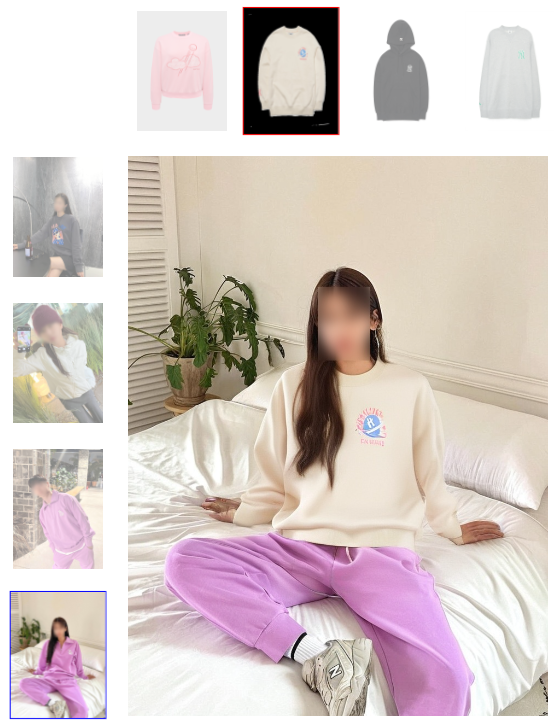
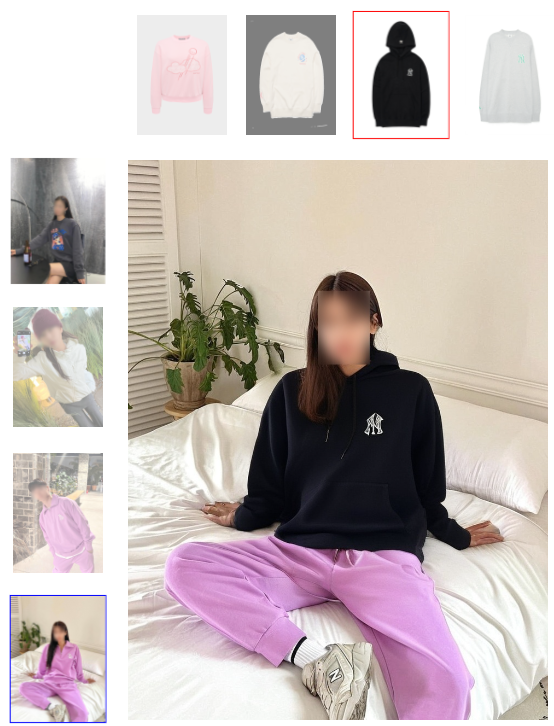
- IDM-VTON 能够生成高保真图像并识别服装的精细细节。多人穿着同一件衣服,显示出衣服细节的一致性。




02 野外虚拟试穿
- 野外虚拟试穿:为了实现野外虚拟试穿(即现实世界场景),我们从互联网和社交媒体平台收集服装图像以及穿着每件服装的人的多个图像。
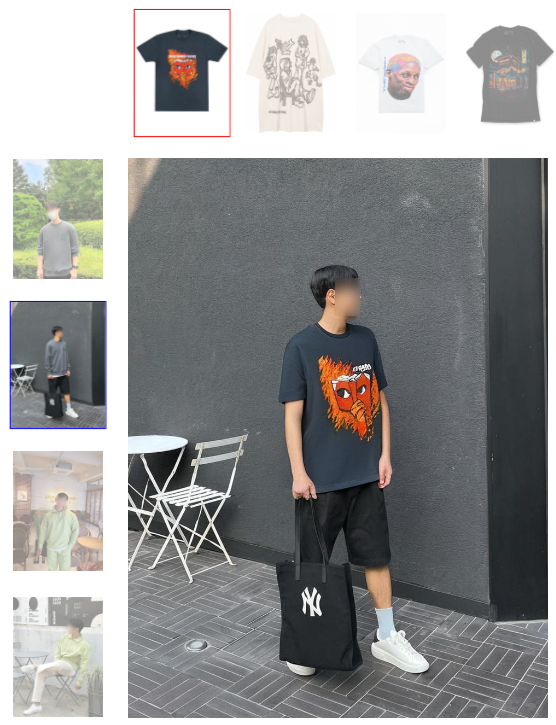

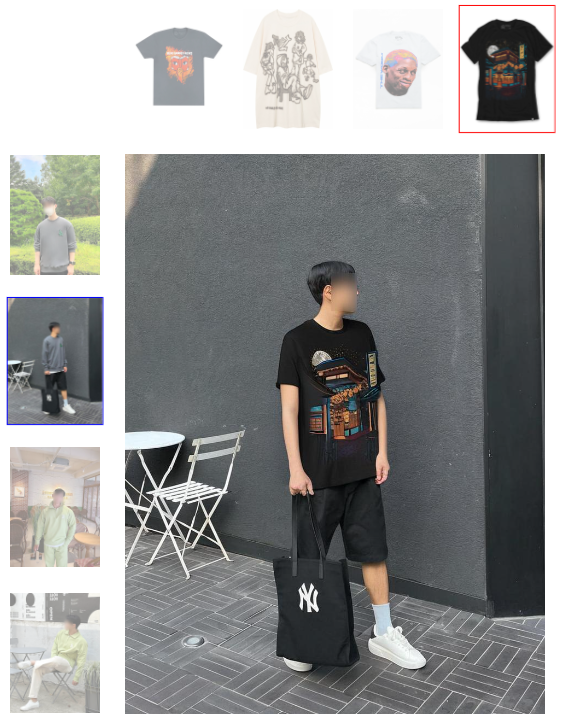
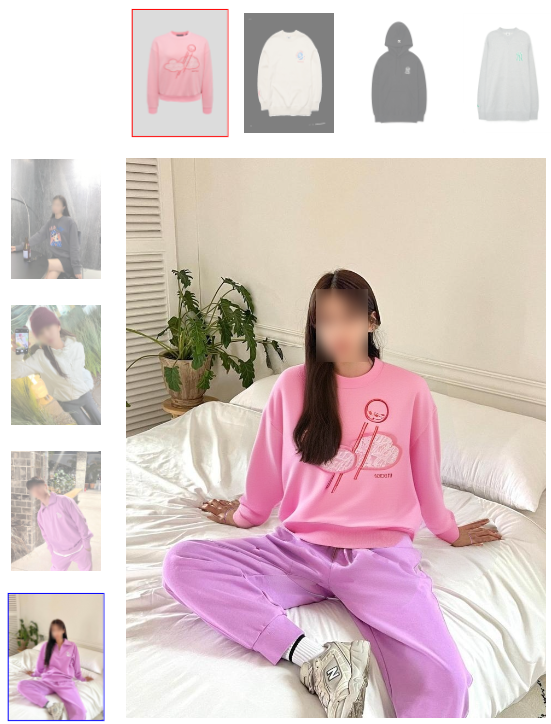

摘要
本文考虑基于图像的虚拟试穿,在给定一对分别描绘人和衣服的图像的情况下,渲染穿着精选服装的人的图像。与其他方法(例如基于 GAN)相比,之前的作品采用现有的基于样本的修复扩散模型进行虚拟试穿,以提高生成的视觉效果的自然度,但它们无法保留服装的身份。为了克服这一限制,我们提出了一种新颖的扩散模型,可以提高服装保真度并生成真实的虚拟试穿图像。
我们的方法被称为 IDM-VTON,使用两个不同的模块来编码服装图像的语义;给定扩散模型的基础 UNet,1)将从视觉编码器提取的高级语义融合到交叉注意力层,然后 2)将从并行 UNet 提取的低级特征融合到自注意力层层。此外,我们还为服装和人物图像提供详细的文字提示,以增强生成视觉效果的真实性。最后,我们提出了一种使用一对人物服装图像的定制方法,该方法显着提高了保真度和真实性。
我们的实验结果表明,我们的方法在保留服装细节和生成真实的虚拟试穿图像方面(无论是定性还是定量)都优于以前的方法(基于扩散和基于 GAN)。此外,所提出的定制方法证明了其在现实场景中的有效性。
方法
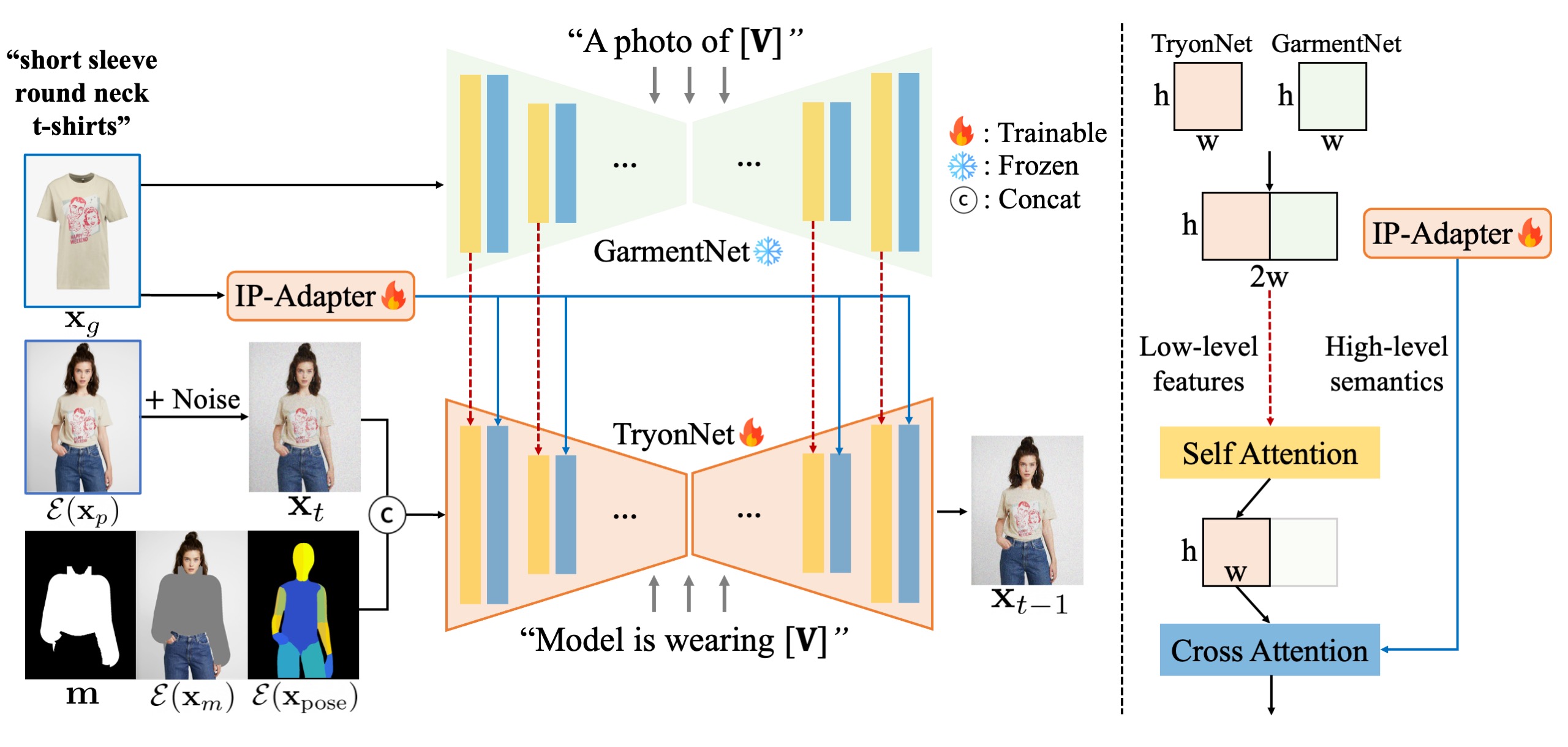
pipeline概述(左):
我们的模型由
1)TryonNet组成,它是处理人物图像的主要UNet,
2)图像提示适配器(IP-Adapter),用于编码服装图像的高级语义,
3)GarmentNet,用于编码低级功能。作为 UNet 的输入,我们将人物图像潜在的噪声潜在与分割掩模、掩模图像和 Densepose 连接起来。
我们为服装提供详细的标题(例如,[V]:“短袖圆领 T 恤”)。然后用于GarmentNet(例如,“[V]的照片”)和TryonNet(例如,“模特穿着[V]”)的输入提示。
注意力模块的详细信息(右):
我们演示了所提出的模型架构和注意力模块的详细信息。 TryonNet 和 GarmentNet 的中间特征被连接并传递到自注意力层,我们使用输出的前半部分(即来自 TryonNet 的部分)。然后我们通过交叉注意力层将输出与文本编码器和 IP 适配器的特征融合。我们微调 TryonNet 和 IP-Adapter 模块,并冻结其他组件。
免费试用
人

衣

试穿效果

[爱研究]AI交流群
为了方便交流,建立了群聊,后台私信发送:666




