⚡[AIGC服务] MegActor | 视频驱动的肖像动画生成
通过原始视频驱动图像,生成肖像动画。即给定一个肖像视频A和一张肖像图像B,即可生成A驱动B的肖像动画。

[TOC]
先睹为快



内容简介
MegActor 是一款无中间表示的肖像动画师,它使用原始视频而不是中间特征作为驱动因素来生成逼真生动的头像视频。
具体来说,我们利用两个 UNet:一个从源图像中提取身份和背景特征,另一个准确地生成并集成直接从原始视频派生的运动特征。
MegActor 可以在低质量的公开数据集上进行训练,并且在面部表情、姿势多样性、微妙的可控性和视觉质量方面表现出色。
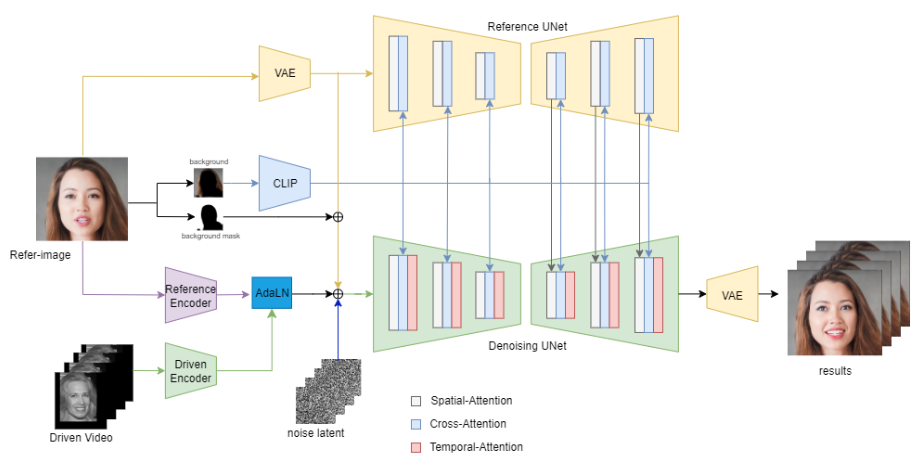
方法总结
背景与挑战
- 原始驱动视频(raw driving videos)包含比传统肖像动画领域中使用的中间表示(如面部标记)更丰富的面部表情信息,但很少作为研究对象。
- 使用原始视频驱动肖像动画存在两个内在挑战:1)显著的身份泄露问题;2)不相关的背景和面部细节(如皱纹)会降低性能。
数据集和预处理
使用公共数据集VFHQ和CelebV-HQ进行训练。
为了解决身份泄露问题,通过AI人脸交换技术和风格化技术(如SDXL)生成训练数据。
使用L2CSNet筛选出具有显著眼球运动的数据,以增强模型对眼球运动的控制。
数据增强
使用pyFacer检测视频中的人脸,并只保留面部区域,将其他区域设置为黑色,减少背景信息泄露。
对驱动视频进行随机增强,包括灰度转换和随机调整大小及纵横比,以增强模型对不同面部形状的泛化能力。
模型架构
- ReferenceNet:使用与去噪UNet网络相同架构的UNet,从参考图像中提取细粒度的身份和背景信息。
- DrivenEncoder:一个轻量级编码器,使用2D卷积层从驱动视频中提取动作特征。
- 时间层(Temporal Layer):在去噪UNet的每个Res-Trans层后插入时间模块,以执行帧间的时间注意力,增强帧的连续性。
- ImageEncoder:使用CLIP的图像编码器替代文本编码器,在交叉注意力中使用。
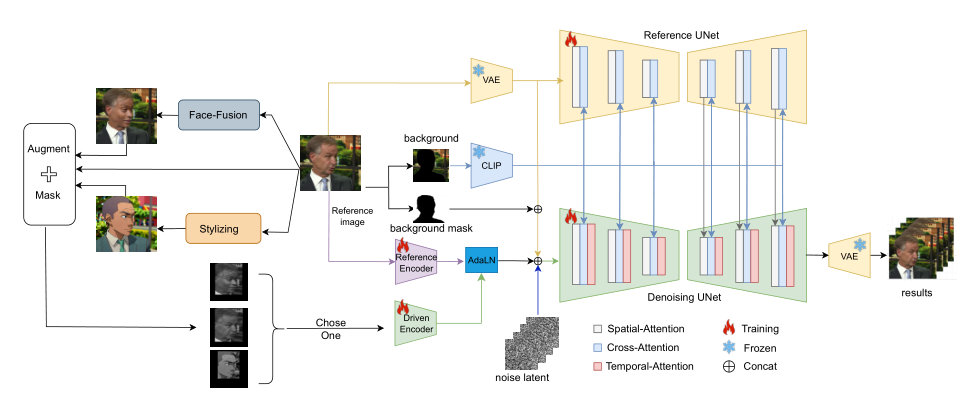
训练技术
训练分为两个阶段:
- 第一阶段:不包括时间层,冻结ImageEncoder,只训练DrivenEncoder、去噪UNet和ReferenceNet。
- 第二阶段:在去噪UNet中插入时间层,只训练时间层。
使用AI人脸交换数据、风格化数据和真实数据作为驱动视频,比例分别为40%、10%和50%。
推理细节
- 在推理阶段,采用重叠滑动窗口方法生成长视频,每次推断16帧,重叠8帧,取两个生成结果在重叠区域的平均值作为最终结果。
贡献与未来工作
- 提出了一种新颖的原始驱动视频控制的肖像动画方法,有效提高了动作一致性并减少了身份泄露问题。
- 增强了对原始驱动视频中无关信息的鲁棒性,通过参考图像的风格化增强了模型的鲁棒性。
- 未来的工作将致力于改进MegActor生成一致视频的能力,特别是在复杂区域如发际线、配饰和嘴巴等,以及评估MegActor流水线与更强大视频生成基础模型(如SDXL)集成的有效性。
应用场景
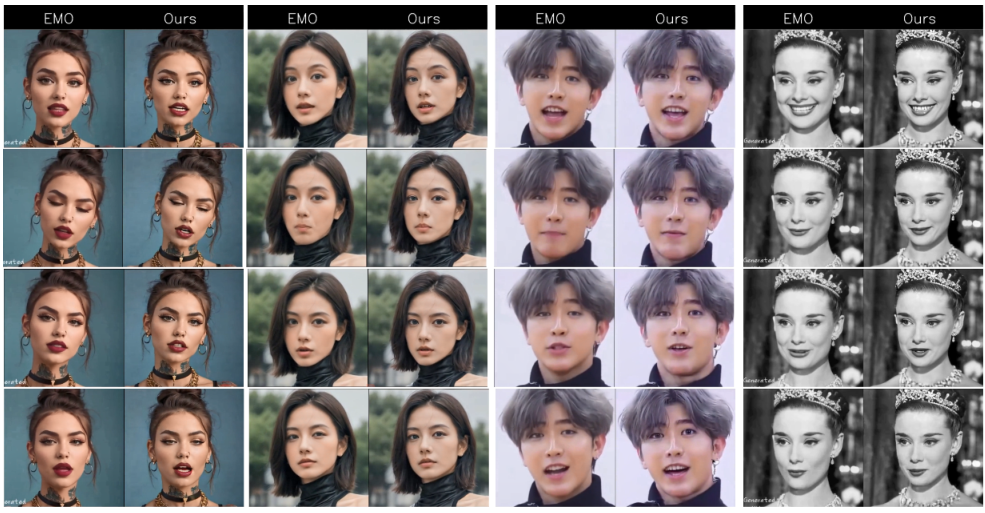
数字虚拟角色(Digital Avatars):
- 创建虚拟形象用于社交媒体、游戏、虚拟现实(VR)和增强现实(AR)体验。
人工智能辅助的人际交流:
- 利用动画肖像进行更加自然和逼真的人机交互,例如客服机器人、智能助手等。
娱乐和媒体制作:
- 在电影、电视和网络媒体中生成高质量的动画角色,降低传统动作捕捉和动画制作的成本。
教育和培训:
- 利用生动的动画角色作为教育工具,提高学习体验的互动性和吸引力。
广告和营销:
- 创造吸引人的动画广告,以提高品牌知名度和市场推广效果。
个性化内容创作:
- 允许用户生成具有个性化特征的动画内容,用于个人娱乐或内容分享。
实时视频会议:
- 在视频会议中使用动画肖像代替真实视频,提供隐私保护或增强表达能力。
艺术创作:
- 艺术家和设计师可以利用这项技术创作新颖的数字艺术作品。
辅助残障人士:
- 通过动画肖像帮助有语言和听力障碍的人士进行交流。
模拟和仿真:
- 在模拟训练和虚拟现实环境中使用动画角色,提供更加真实的交互体验。
文化遗产保护:
- 利用肖像动画技术复原历史人物,用于教育和展览。
法律和安全:
- 在需要匿名化处理的场景中,使用动画肖像代替真实人物的面部,保护隐私。
随着技术的不断进步和优化,MegActor模型及其衍生技术有望在上述领域中发挥重要作用,推动相关行业的创新和发展。
免费试用
需要可私信联系
[爱研究]AI交流群
为了方便交流,建立了群聊,后台私信发送:666




