FreeU: Free Lunch in Diffusion U-Net

Methodology
Overview
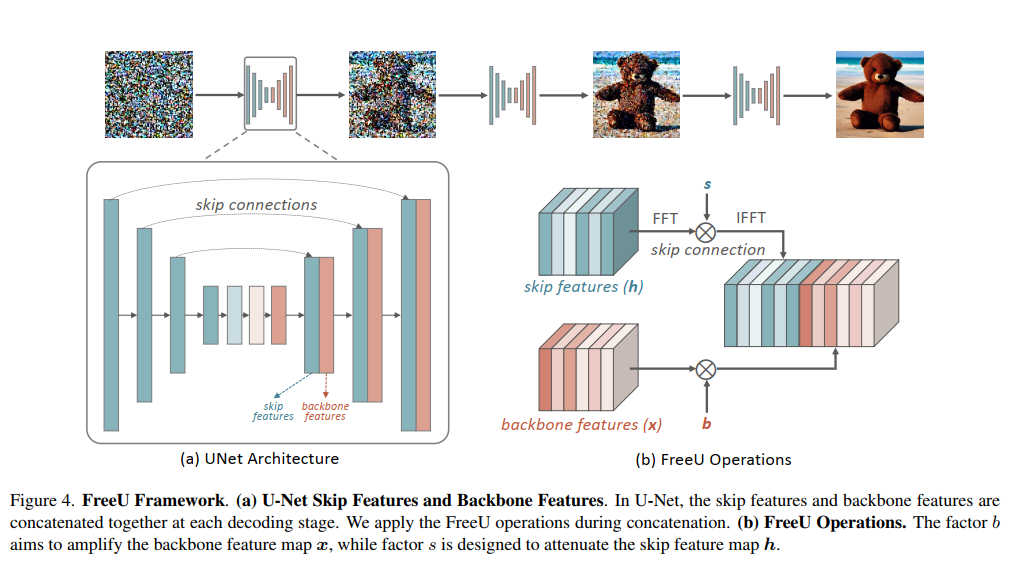
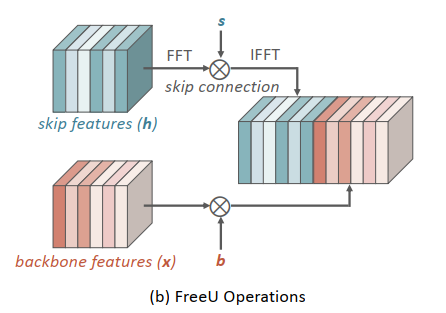
FreeU Operations
通常U-Net会将跳层特征(蓝色)和骨干特征(橙色)拼接concat后传入下一层
s表示跳跃连接特征权重,b表示骨干特征权重
对skip features通过FFT变换到频域,乘上权重s,在通过IFFT反变换
对backbone features乘上权重b
将二者特征拼接
- 骨干特征部分增强
- 如果全部通道都乘上b放大,会导致最终的图像变得过度平滑,所以只对其中一半通道内特征进行放大
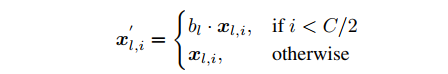
- 跳层特征选择弱化
- 为了进一步缓解因增强去噪而导致的纹理过度平滑问题,我们进一步采用了傅立叶域中的频谱调制技术。有选择性地减弱跳层特征的低频成分。
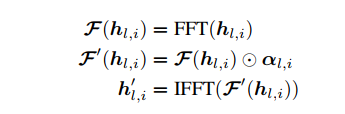
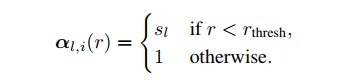
Experiments
Denoising process
- 最上面一行展示了图像在迭代过程中的渐进式去噪过程,随后两行则展示了反傅里叶变换后的低频和高频分量。与每一步相匹配。很明显
在去噪过程中,低频成分变化缓慢,而高频成分的变化则更为显著。

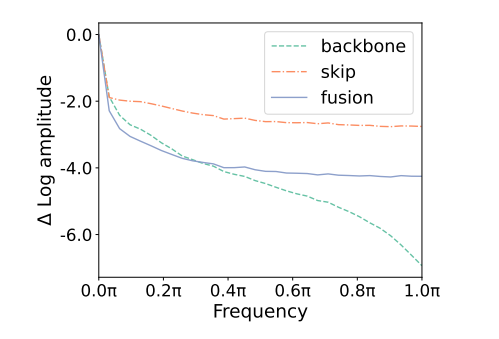
Effect of backbone and skip connection scaling factors
- 提高骨干缩放因子 b 能显著提高图像质量,而跳过缩放因子 s 的变化对图像合成的影响微乎其微。

- 跳跃特征skip各个频率中的分量较为均衡,而骨干特征backbone大多都是低频成分,所以增强b才会出现图像越来越平滑的现象,增强s时,因为s在频域分布比较均衡,所以对图像影响有限。
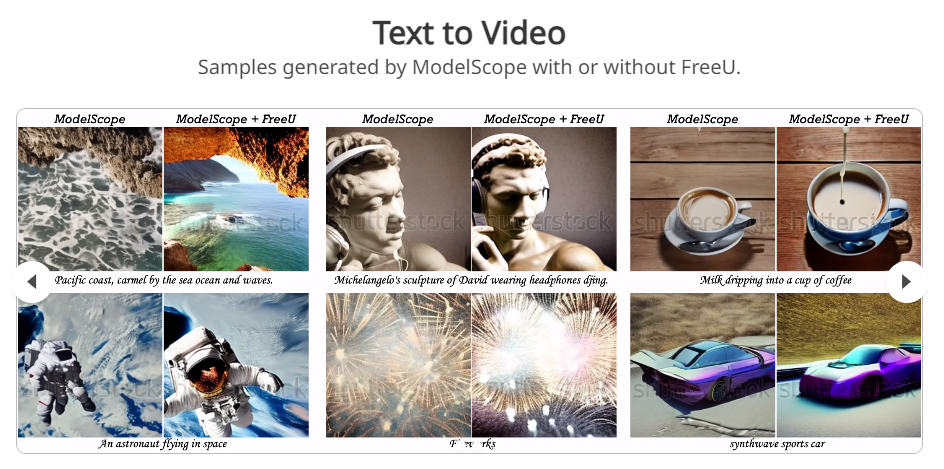
Results

Code
Official FreeU Code
- 在去噪Unet中只对前2个阶段进行操作
def Fourier_filter(x, threshold, scale):
# FFT
x_freq = fft.fftn(x, dim=(-2, -1))
x_freq = fft.fftshift(x_freq, dim=(-2, -1))
B, C, H, W = x_freq.shape
mask = torch.ones((B, C, H, W)).cuda()
crow, ccol = H // 2, W //2
mask[..., crow - threshold:crow + threshold, ccol - threshold:ccol + threshold] = scale
x_freq = x_freq * mask
# IFFT
x_freq = fft.ifftshift(x_freq, dim=(-2, -1))
x_filtered = fft.ifftn(x_freq, dim=(-2, -1)).real
return x_filtered
class Free_UNetModel(UNetModel):
"""
:param b1: backbone factor of the first stage block of decoder.
:param b2: backbone factor of the second stage block of decoder.
:param s1: skip factor of the first stage block of decoder.
:param s2: skip factor of the second stage block of decoder.
"""
def forward(self, x, timesteps=None, context=None, y=None, **kwargs):
for module in self.output_blocks:
hs_ = hs.pop()
# --------------- FreeU code -----------------------
# Only operate on the first two stages
if h.shape[1] == 1280:
h[:,:640] = h[:,:640] * self.b1
hs_ = Fourier_filter(hs_, threshold=1, scale=self.s1)
if h.shape[1] == 640:
h[:,:320] = h[:,:320] * self.b2
hs_ = Fourier_filter(hs_, threshold=1, scale=self.s2)
# ---------------------------------------------------------
h = th.cat([h, hs_], dim=1)
h = module(h, emb, context)
h = h.type(x.dtype)
if self.predict_codebook_ids:
return self.id_predictor(h)
else:
return self.out(h)Parameters
请根据您的模型、图像/视频风格或任务调整这些参数。以下参数仅供参考。
SD1.4
b1: 1.2, b2: 1.4, s1: 0.9, s2: 0.2
SD2.1
b1: 1.1, b2: 1.2, s1: 0.9, s2: 0.2
Range for More Parameters
When trying additional parameters, consider the following ranges:
- b1: 1 ≤ b1 ≤ 1.2
- b2: 1.2 ≤ b2 ≤ 1.6
- s1: s1 ≤ 1
- s2: s2 ≤ 1
FreeU + Diffusers
from diffusers import StableDiffusionPipeline
import torch
from .free_lunch_utils import register_free_upblock2d, register_free_crossattn_upblock2d
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# -------- freeu block registration
register_free_upblock2d(pipe, b1=1.2, b2=1.4, s1=0.9, s2=0.2)
register_free_crossattn_upblock2d(pipe, b1=1.2, b2=1.4, s1=0.9, s2=0.2)
# -------- freeu block registration
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")Conclusions
- 即插即用来提高扩散模型的生成质量,不需要训练和额外的参数,可以应用到所有扩散模型中,包括各种基于扩散模型的图像、视频生成任务
- Unet中跳跃连接贡献更多高频细节但会可能会影响去噪能力,骨干连接贡献更多去噪能力,选择性提高基础连接权重并降低跳跃连接中低频权重可提高生成质量
- 实验文章,鸡肋



