
Abstract
DALL-E 3 能够理解的细微差别和细节明显多于我们以前的dalle1/2系统,让您可以轻松地将您的想法转化为异常精确的图像。
现代文本到图像系统往往会忽略文字或描述,迫使用户学习提示工程。DALL-E 3 代表着我们在生成与您提供的文本完全一致的图像能力方面的一次飞跃。
DALL-E 3 是在 ChatGPT 的基础上开发的,它可以让你把 ChatGPT 作为你的头脑风暴伙伴和提示的改进者。您只需向 ChatGPT 提出您的要求,从一个简单的句子到一个详细的段落都可以。
当您提出一个想法时,ChatGPT 会自动为DALL-E 3生成量身定制的详细提示,让您的想法栩栩如生。如果您喜欢某个图像,但它不太合适,您可以要求 ChatGPT 进行调整,只需几个字即可。
DALL-E 3 将于 10 月初向 ChatGPT Plus 和企业客户推出。与 DALL-E 2 一样,您使用 DALL-E 3 创建的图片归您所有,您无需获得我们的许可即可对其进行转载、销售或商品化。
- OpenAI 的新图像人工智能 DALL-E 3 目前正在 ChatGPT 和必应图像创建器中部署。OpenAI 试图通过检查提示是否有违规行为,并在违规行为似乎是无意的情况下对其进行改写,从而防止创建有害或冒犯性的图片。
- OpenAI 还训练了一个单独的图像分类器,以检测和防止性别歧视或攻击性内容。新版 DALL-E 3 已将生成此类图像的风险降低到 0.7%。不过,OpenAI 写道,DALL-E 3 仍然存在文化偏见,总体上偏向西方文化,尤其是在非特定查询方面。
- 关于版权问题,OpenAI 指出,它无法预测每一种情况或组合,因此,尽管采取了所有保障措施,但生成的图像中仍可能出现受版权保护的材料。
Methodology
Overview
DALL·E 3 System Card
2023年10月3号,由OpenAI发布
1 Introduction
DALL-E 3 是一个人工智能系统,它将文本提示作为输入,并生成新图像作为输出。DALL-E 3 建立在 DALL-E 2的基础上,提高了字幕保真度和图像质量。
DALL-E 3 集成到了 ChatGPT / GPT-4中,流程是:
用户提供相对模糊的图像请求描述 -> GPT4 -> 生成细节提示词 -> DALL-E 3 -> 生成高质量细节图像(降低了用户描述和图像质量的GAP)
1.1 Mitigation Stack
数据过滤:暴力等不健康的内容
过滤算法:在DALL-E 2基础上,降低了暴力等宽泛过滤阈值。降低这些过滤器的选择性,可以增加我们的训练数据集,减少模型对生成女性的偏差
安全措施:
- ChatGPT:会拒绝用户输入的不健康内容
- 提示输入分类器:识别ChatGPT和用户对话中可能侵犯使用政策的信息并拒绝
- 拦截列表:我们根据以前在 DALL-E 2 上的工作、主动风险发现和早期用户的结果,维护了各种类别的文本屏蔽列表
- 提示转化:ChatGPT 可改写已提交的文本,以便更有效地进行提示
DALL-E 3 更有效。该流程还用于确保提示符合我们的准则,包括删除公众人物的名字,以特定属性的人物为基础、并以通用方式书写品牌对象 - 图像输出分类器: 开发了图像分类器,可对 DALL-E 3 生成的图像进行分类。如果这些分类器被激活,可能会在输出之前阻止图像。
2 Deployment Preparation
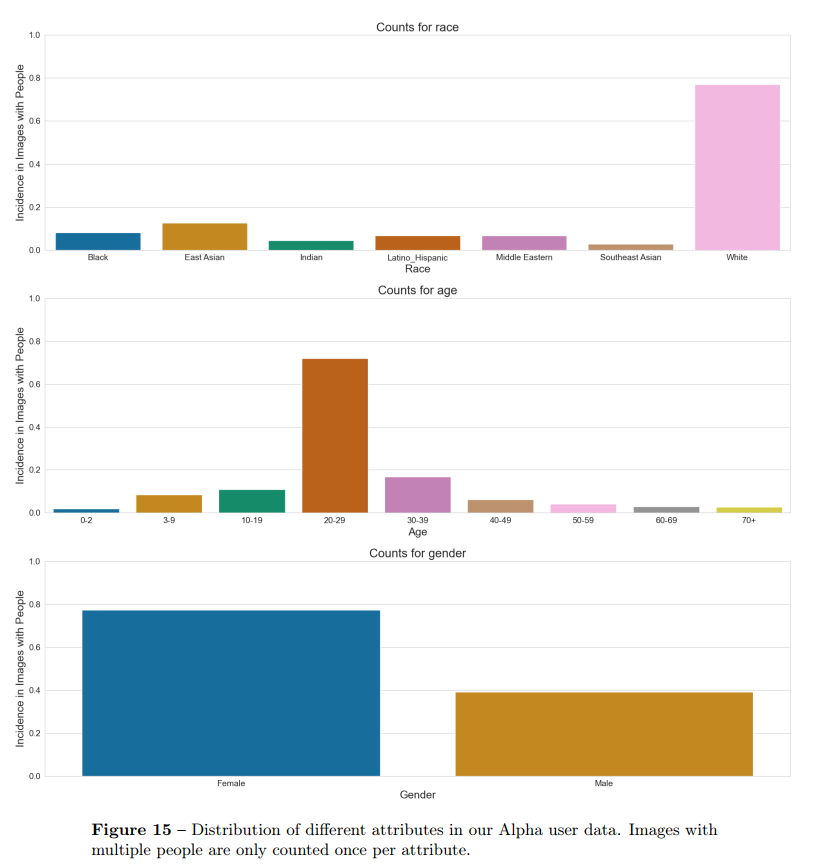
早起版本中先测试,分析了这些部署所产生的数据,以进一步改进 DALL-E 3 在风险领域的行为,如公众人物世代、人口偏见和sexual内容。我们发现,在试验中,包含人物描写的图片主要倾向于白人、年轻人和女性。为此,我们调整了 ChatGPT 的的用户提示转换,以指定更多样化的人物描述。
大量的风险分析以及分类器等缓解措施,降低不健康内容的出现概率
- 比如不穿衣服,不行

- 比如公众人物,不行

- 比如艺术家风格作品,不行

- ……,侵权的不行,那还搞啥,他喵的!

- 描述越详细越好,也就是附加多种属性

- 年龄、性别、人种分布(20-29岁,白种人,女性 占大头)
3 DALL-E 3 体验入口
微软的Bing浏览器可以,但是国内被屏蔽
4 改进总结
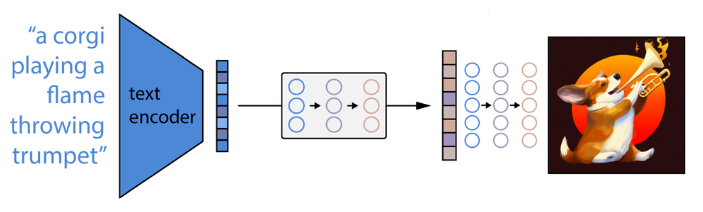
DALL-E 2 原理
CLIP文本编码器将图像描述映射到表示空间;
然后扩散先验从CLIP文本编码映射到相应的CLIP图像编码;
最后,修改版的GLIDE生成模型通过反向扩散从表示空间映射到图像空间,生成众多可能图像中的一个
海量数据对
- DALL-E 3 改进
- 最大的改进,就是样本质量的提高,其次模型结构微调了(论文未披露),最后就是GPT加持提示词转化精度更高
Paper 2 Improving Image Generation with Better Captions
1 Abstract
- 文生图模型可以通过在高度描述性生成的图像字幕上训练来提升提示词能力
- 现存的研究主要是沿着详细的图像描述而忽略了单词和混淆提示(歧义),在数据集上表现为噪声和不准确,从而影响精度
- DALL-E 3 通过训练一个定制的图像字母器对训练集重新生成字幕,并用它们训练数据集,最后公开了样例和评估代码
2 Dataset Recaptioning
训练用的文本图像对中,文本字幕通常来源于人类标注,其主要关注主体对象,而忽略了背景细节或者图像中颜色等感知关系,而这些缺点都可以通过合成生成字幕解决。被忽略的细节如下:
- 厨房里的水槽或人行道上的停车标志等物体的存在,以及对这些物体的描述。
这些物体。 - 物体在场景中的位置和数量。
- 常识细节,如场景中物体的颜色和大小。
- 图像中显示的文字
2.1 Building an image captioner
i: imaget: token
Step 1 将输入的文本字符化,将离散的字符用序列表征,t = [t1, t2, . . . , tn]
Step 2 构建一个语言模型 Model A ,最大化似然函数 L(t)
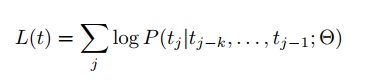
Step 3 在Model A 基础上构建 图像字幕生成器 Model B,考虑到图像像素空间太大,需要通过CLIP压缩图像表征空间F(i),最大化似然函数L(t,i)
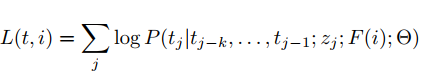
Step 4 将Model A和Model B 联和训练
2.1.1 Fine-tuning the captioner
Stage 1 SSC
- 先构造一个小的只对图像主体描述的字幕数据集,模型偏好生成图像主体的提示词,这一步微调叫做 short synthetic captions
Stage 2 DSC
- 再构造一个大的详细描述的字幕数据集,包括图像中主体及其环境、背景、文字、风格、颜色等细节,再次进行微调,这一步叫做 descriptive synthetic captions
3 Results


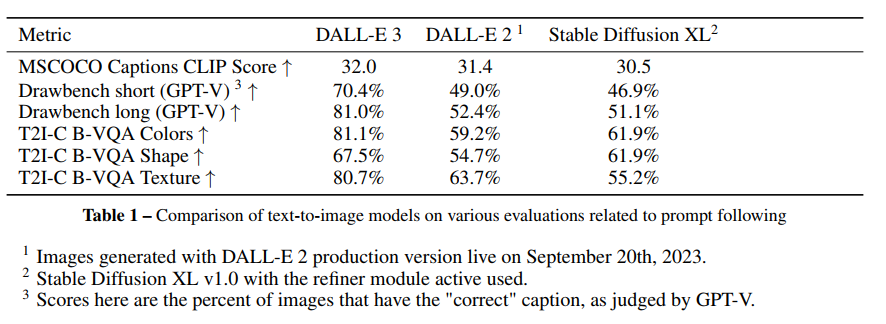
4 Limitations & Risk
Spatial awareness
在对象定位和空间感知方面存在困难。例如,使用词语 “在左边”、”在下面”、”在后面” 等是相当不可靠的。这是因为我们的合成字幕生成器也有这个弱点:它在陈述对象位置方面不可靠,这反映在我们的下游模型中。
Text rendering
在构建我们的字幕生成器时,我们特别注意确保它能够在生成的字幕中包含在图像中找到的显著单词。因此,DALL-E3 可以在提供提示时生成文本。在测试过程中,我们注意到这种功能不够可靠,因为单词可能丢失或多余字符。我们怀疑这可能与我们使用的 T5 文本编码器有关:当模型遇到提示中的文本时,实际上它会看到代表整个单词的标记,并必须将这些标记映射到图像中的字母。
Specificity
我们观察到我们的合成标题容易产生关于图像的重要细节的幻觉。例如,给定一幅花的植物图,字幕生成器通常会幻想一个植物的属和种,并将其放入标题中,即使这些细节在图像中以文本形式可用。当描述鸟类图片时,我们观察到类似的行为:物种可能被幻想,或者根本不提到。这对我们的文本到图像模型产生了下游影响:DALL-E3 在为上述特定术语生成图像方面不可靠
Experiments




Conclusions
- 现在不需要提示词工程了,直接和chatGPT对话迭代修改到您满意(你的想法和生成的图像高度匹配)
- 图像生成质量堪比Midjourney,由于加持了ChatGPT,DALLE3对提示词的理解会更加准确
- 太牛13了,666,我都看笑了




