Controlling Vision-Language Models for Universal Image Restoration
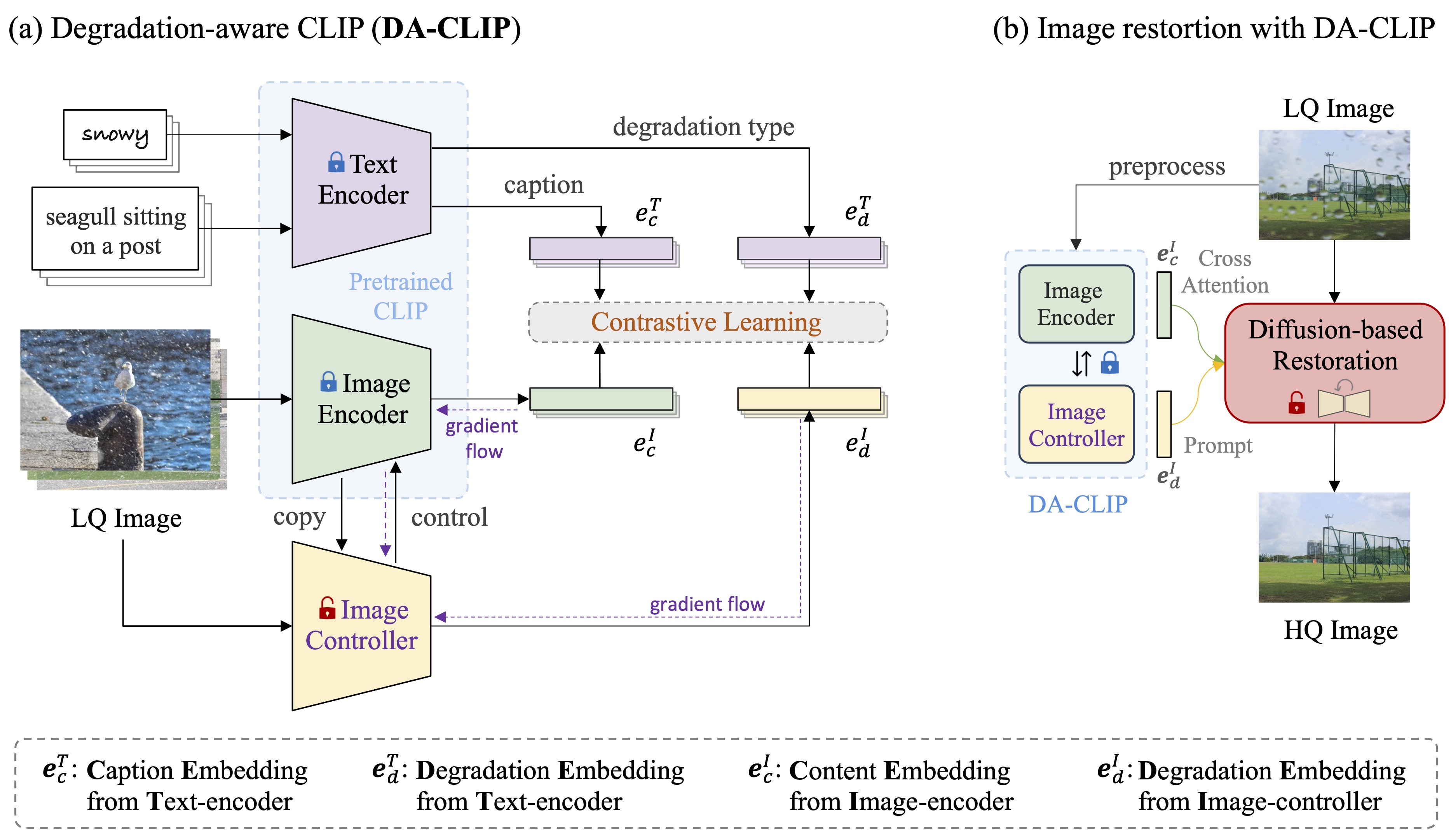
Methodology
Overview
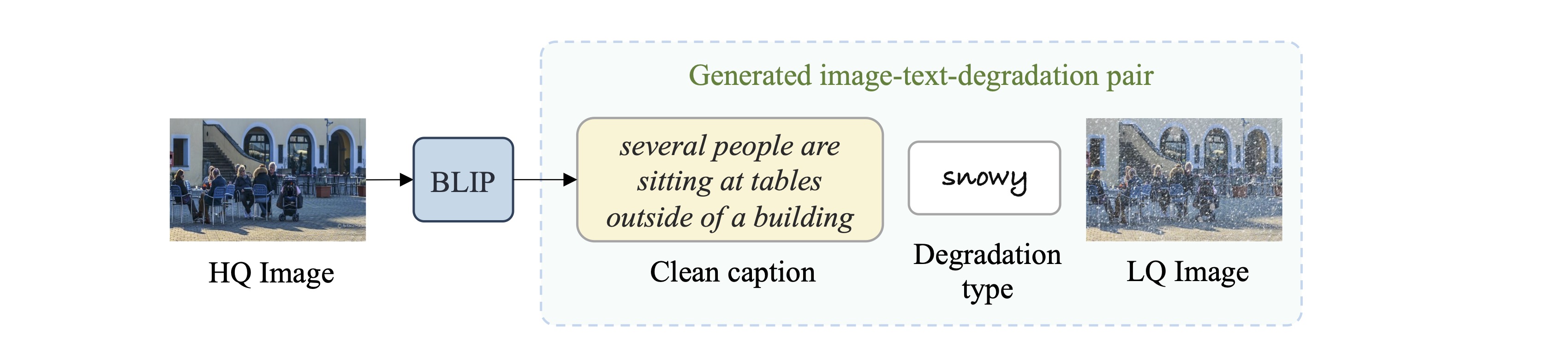
Generating Image-Text-Degradation Pairs
- 为了在混合降解数据集上训练 DA-CLIP,我们使用引导式视觉语言框架 BLIP 为所有 HQ 图像生成合成字幕。由于输入是干净的,因此假定生成的字幕是准确和高质量的。然后,我们可以直接将这些干净的标题、LQ 图像和相应的降解类型结合起来,构建图像-文本-降解对。
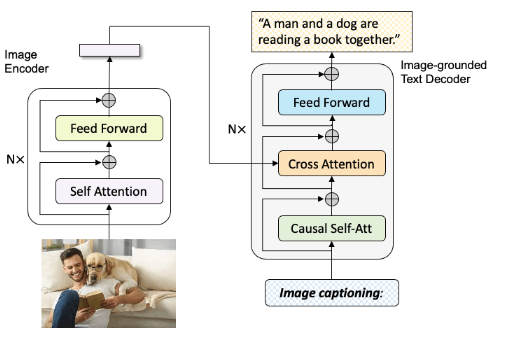
BLIP
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP是引导语言图像预训练,实现统一的视觉语言理解和生成
- https://github.com/salesforce/BLIP
- 输入图像images,输出字母caption,就可以构造图文数据集
- https://github.com/salesforce/LAVIS BLIP集成到了LAVIS里面
- Image Description Generation 功能可以构造数据
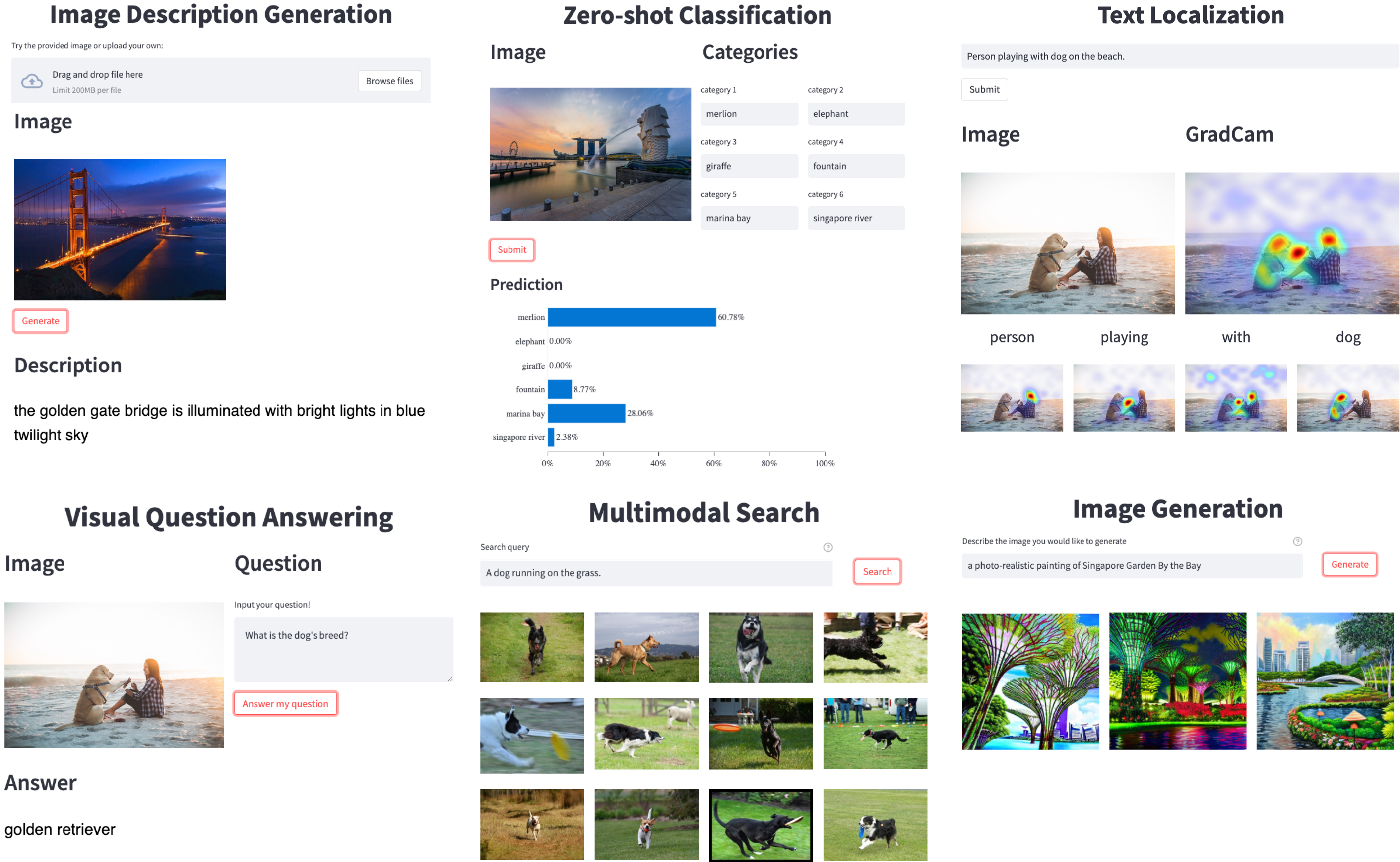
Testing Result
- https://colab.research.google.com/github/salesforce/BLIP/blob/main/demo.ipynb
- Note: comment specific transformers version
# !pip3 install transformers==4.15.0 timm==0.4.12 fairscale==0.4.4
!pip3 install transformers timm==0.4.12 fairscale==0.4.4- Example 1
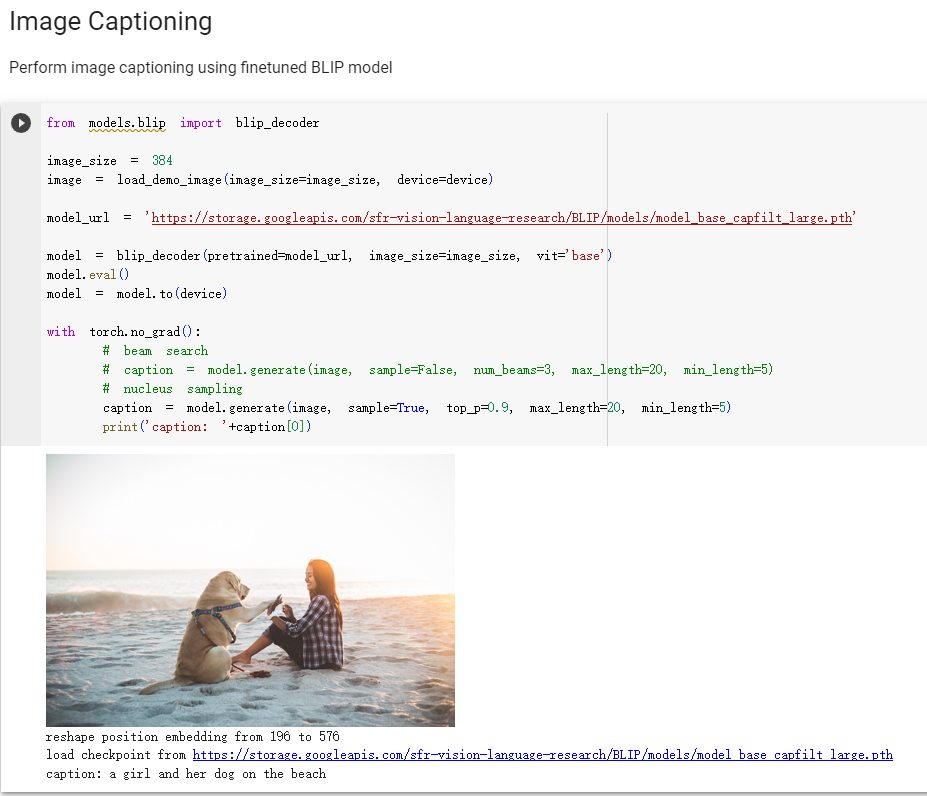
- Example 2
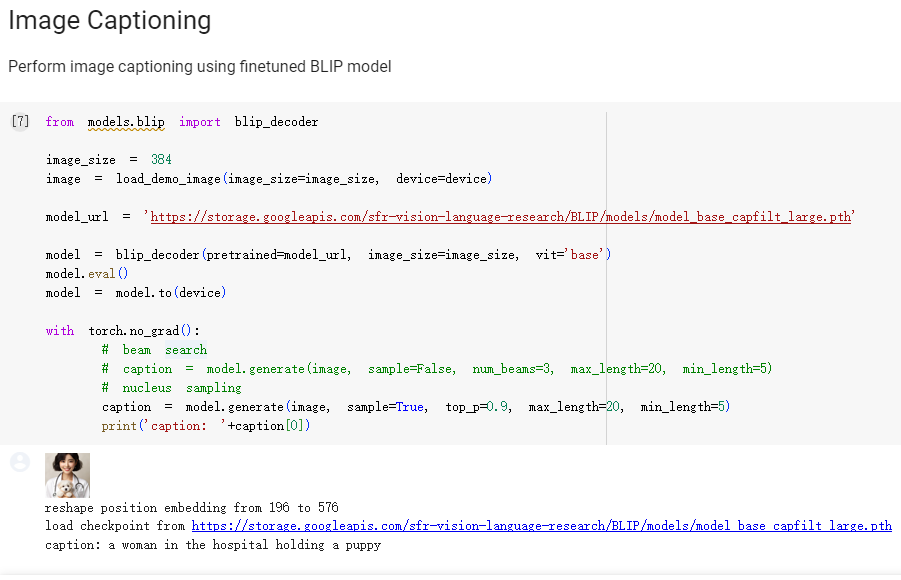
Experiments
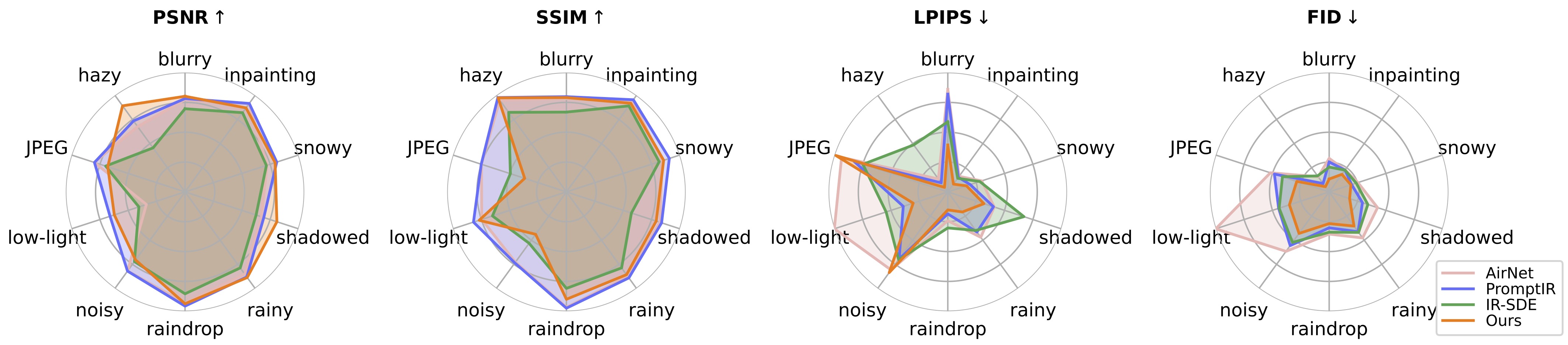

Conclusions
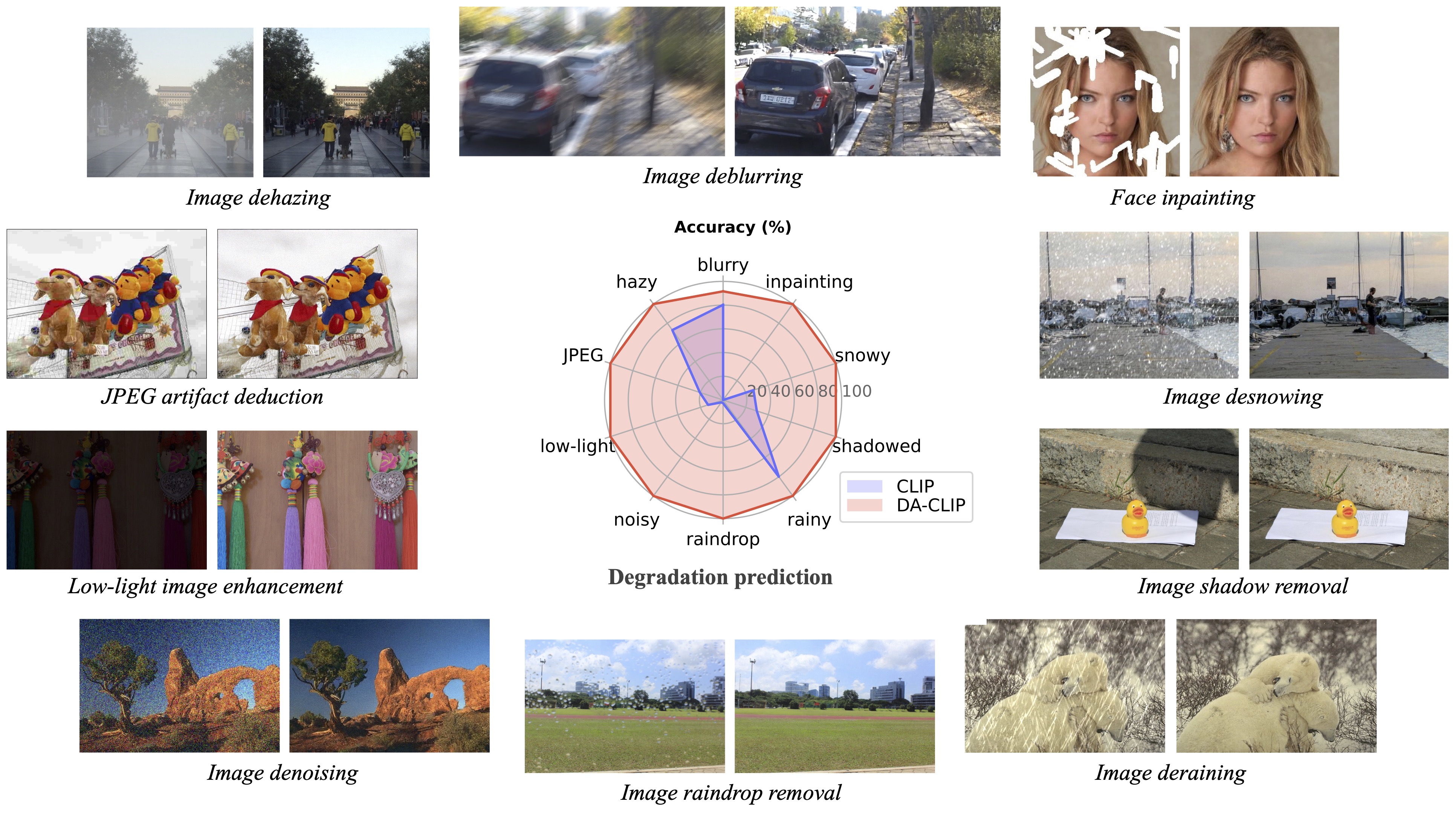
图像修复多种应用场景
- 人脸修复
- 去雨
- 去雪
- 去影子
- 去伪影
- 去噪
- 低光照图像增强
BLIP只能粗粒度的图像描述,缺少足够的属性,可用于构造图文数据集


